Mellum by JetBrains
Mellum par JetBrains : Le LLM Open-Source pour une Inférence Ultra-Rapide et Performante
Découvrez Mellum, la nouvelle famille de modèles de langage (LLM) open-source de JetBrains. Conçu pour l'inférence à ultra-faible latence et la haute performance, Mellum2 utilise une architecture Mixture-of-Experts (MoE) de 12B paramètres pour optimiser les flux de travail de développement réels. Réduisez vos coûts d'inférence de moitié tout en profitant d'une rapidité exceptionnelle pour la génération de code, les pipelines RAG et le déploiement local privé.
2026-06-22
--K

Mellum by JetBrains Informations sur le produit
Mellum par JetBrains : L'Excellence du LLM Open-Source pour le Développement
Dans le paysage technologique actuel, la rapidité et l'efficacité de l'intelligence artificielle sont devenues des enjeux cruciaux pour les développeurs. Mellum, la nouvelle famille de modèles de langage (LLM) de JetBrains, s'impose comme une solution incontournable. Ce LLM open-source est spécifiquement optimisé pour les flux de travail de développement réels, où la latence et la performance sont des facteurs déterminants pour la productivité.
Qu'est-ce que Mellum ?
Mellum est une famille de modèles de langage rapides développée par JetBrains. Elle comprend notamment des modèles de nouvelle génération conçus pour offrir une inférence à ultra-faible latence et une performance de haut niveau. Contrairement à d'autres solutions génériques, le modèle Mellum est bâti pour répondre aux exigences des environnements de développement professionnels.
En tant qu'outil open-source, Mellum permet aux ingénieurs en IA, aux chercheurs et aux développeurs d'accéder à une technologie de pointe capable de comprendre non seulement le code, mais aussi le contexte et l'intention derrière chaque ligne. Que ce soit pour la complétion de code ou des tâches de programmation complexes, Mellum se distingue par sa capacité à traiter le langage naturel en harmonie avec les langages de programmation.
Les Caractéristiques de Mellum
Le succès de Mellum repose sur une série d'innovations techniques et de choix architecturaux qui privilégient l'efficacité opérationnelle.
Une Architecture Mixture-of-Experts (MoE)
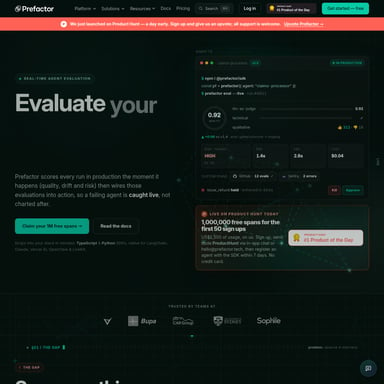
Le modèle Mellum2 s'appuie sur une architecture de type Mixture-of-Experts (MoE) avec 12 milliards de paramètres (12B). Cette conception permet d'apporter les capacités avancées du MoE à une classe de modèles beaucoup plus compacte. Grâce à cette architecture, Mellum offre une inférence à ultra-faible latence et un débit élevé, se révélant souvent deux fois plus rapide que les modèles de taille similaire.
Haute Performance et Coût Réduit
L'un des avantages majeurs de Mellum est son efficacité économique. En utilisant moins de paramètres actifs par requête et en optimisant l'utilisation du calcul, Mellum parvient à diviser par deux les coûts d'inférence. Malgré cette réduction des coûts, la qualité du codage reste excellente, offrant ainsi un équilibre parfait entre budget et performance.
Fiabilité et Transparence
JetBrains a formé Mellum sur des données transparentes, garantissant un alignement cohérent du modèle. Cette approche assure une fiabilité indispensable pour les applications critiques. De plus, le modèle est flexible : il peut être affiné (fine-tuned) et déployé selon vos besoins spécifiques.
Flexibilité de Déploiement
Mellum offre un contrôle total sur l'infrastructure. Les utilisateurs peuvent choisir de déployer le modèle :
- Localement : Pour un contrôle maximal de la confidentialité et de la souveraineté des données.
- Sur le cloud : Pour bénéficier d'une scalabilité adaptée aux charges de travail importantes.
Les Modèles de la Gamme Mellum
La famille Mellum se décompose en plusieurs versions adaptées à des usages précis :
Mellum2 : Le Champion de la Performance
Mellum2 est le choix idéal pour l'inférence à haute performance. Avec ses 12B paramètres et son architecture MoE, il combine des capacités linguistiques et de codage robustes avec une efficacité exceptionnelle pour les flux de travail en temps réel.
Mellum1 : L'Expert en Génération de Code
Mellum1 est un modèle open-source spécialisé dans le codage. Il est conçu pour une compréhension large du code et une complétion efficace à travers de multiples langages de programmation.
Cas d'Utilisation de Mellum
Mellum ne se contente pas de générer du code ; il s'intègre au cœur des systèmes IA modernes pour transformer l'impact technologique.
Routage et Orchestration des Flux IA
Mellum peut analyser les requêtes entrantes pour sélectionner le modèle le plus approprié à chaque tâche. Ce routage intelligent permet d'optimiser les ressources entre différents modèles en fonction des exigences spécifiques du cas d'utilisation.
Pipelines RAG à Faible Latence
Dans les systèmes de génération augmentée par récupération (RAG), la vitesse est essentielle. Mellum permet de récupérer les informations pertinentes et de générer des réponses ou des résumés de manière quasi instantanée, garantissant la réactivité des systèmes de questions-réponses.
Agents Spécialisés dans les Workflows Complexes
Au lieu de dépendre d'un seul grand modèle coûteux, les développeurs peuvent utiliser Mellum pour alimenter des sous-agents rapides au sein de pipelines complexes. Ces agents peuvent se charger de tâches spécialisées comme la planification, la validation ou la collecte de contexte.
IA Privée et Souveraine
Pour les entreprises soucieuses de la sécurité, Mellum permet une utilisation locale de l'IA. En hébergeant le modèle sur vos propres serveurs, vous gardez une maîtrise totale sur votre code et vos données sensibles.
Comment Utiliser Mellum
L'intégration de Mellum dans vos projets est facilitée par sa nature open-source et sa polyvalence.
- Choix de l'environnement : Déterminez si votre infrastructure nécessite un déploiement local pour la confidentialité ou une instance cloud pour la performance.
- Configuration du modèle : Utilisez Mellum2 pour les tâches nécessitant une latence minimale ou Mellum1 pour les besoins intensifs en génération de code multi-langages.
- Déploiement : Mettez en œuvre le modèle dans vos pipelines existants, qu'il s'agisse de systèmes RAG, d'agents spécialisés ou d'outils de complétion de code.
- Optimisation : Profitez des capacités d'ajustement (fine-tuning) pour aligner les performances de Mellum avec vos standards internes de développement.
FAQ (Foire Aux Questions)
Qu'est-ce que Mellum ? Mellum est une famille de modèles de langage (LLM) open-source créés par JetBrains, optimisés pour la performance, la faible latence et les flux de travail de développement.
En quoi la dernière version de Mellum est-elle différente des précédentes ? Mellum2 introduit une architecture Mixture-of-Experts (MoE) de 12B paramètres, offrant une vitesse deux fois supérieure et une efficacité accrue par rapport aux modèles standards.
Pourquoi ne pas simplement utiliser un grand modèle comme GPT ? Mellum est conçu pour les tâches où la latence et le coût sont critiques. Il permet une exécution plus rapide et moins onéreuse pour des tâches spécifiques de codage et de développement sans sacrifier la qualité.
Comment Mellum2 est-il entraîné ? Le modèle est entraîné sur des données transparentes et aligné pour assurer une cohérence et une fiabilité maximales dans les environnements de production.
Quelle est la performance de Mellum ? Mellum offre une inférence ultra-rapide, souvent 2x plus rapide que ses concurrents de taille équivalente, avec une excellente qualité de compréhension du code.
Qu'est-ce qui rend Mellum rentable ? Sa rentabilité provient de son architecture MoE qui utilise moins de paramètres actifs par requête, réduisant ainsi de moitié les coûts d'inférence par rapport aux modèles traditionnels.
Quels langages sont supportés ? Mellum supporte une large compréhension et génération de code à travers de multiples langages de programmation.
Mellum est-il open-source ? Oui, Mellum est un modèle open-source, permettant une personnalisation et un déploiement flexibles, que ce soit localement ou sur le cloud.