Mellum by JetBrains
Mellum od JetBrains: Otwarty model LLM o ultra-niskim opóźnieniu i wysokiej wydajności dla programistów
Mellum to rodzina szybkich modeli językowych LLM od JetBrains, zoptymalizowana pod kątem rzeczywistych przepływów pracy programistycznej. Dzięki architekturze Mixture-of-Experts (MoE), Mellum2 oferuje ultra-niską latencję, wysoką wydajność i niższe koszty inferencji. Modele te wspierają zadania związane z kodem i językiem naturalnym, oferując elastyczność wdrożenia lokalnego oraz w chmurze.
2026-06-22
--K

Mellum by JetBrains Informacje o produkcie
Mellum: Nowoczesne modele LLM od JetBrains dla wydajnego programowania
W dobie dynamicznego rozwoju sztucznej inteligencji, programiści i inżynierowie AI/ML poszukują rozwiązań, które nie tylko oferują wysoką jakość generowanych odpowiedzi, ale przede wszystkim charakteryzują się szybkością i efektywnością kosztową. JetBrains, lider w dziedzinie narzędzi programistycznych, wprowadza Mellum – rodzinę szybkich modeli językowych (LLM), w tym przełomowy model Mellum2, zaprojektowany z myślą o ultra-niskim opóźnieniu i wysokiej wydajności inferencji.
Czym jest Mellum?
Mellum to opracowany przez JetBrains otwarty model LLM (Large Language Model), który został zoptymalizowany pod kątem rzeczywistych przepływów pracy w programowaniu. W przeciwieństwie do ogólnych modeli językowych, Mellum koncentruje się na zadaniach, w których kluczowe znaczenie mają latencja i wydajność. Jest to rozwiązanie dedykowane dla programistów, zespołów przechodzących z fazy eksperymentalnej do produkcyjnej oraz badaczy AI.
Rodzina Mellum obejmuje modele takie jak Mellum2, będący modelem typu Mixture-of-Experts (MoE) o 12 miliardach parametrów, oraz Mellum1, wyspecjalizowany w generowaniu kodu o wysokiej jakości. Dzięki swojej architekturze, modele te doskonale radzą sobie zarówno z zadaniami programistycznymi, jak i przetwarzaniem języka naturalnego, rozumiejąc kontekst oraz intencje użytkownika.
Kluczowe cechy i korzyści modelu Mellum
Wykorzystanie Mellum w codziennej pracy programistycznej niesie ze sobą szereg korzyści, które wyróżniają te modele na tle konkurencji:
1. Architektura Mixture-of-Experts (MoE)
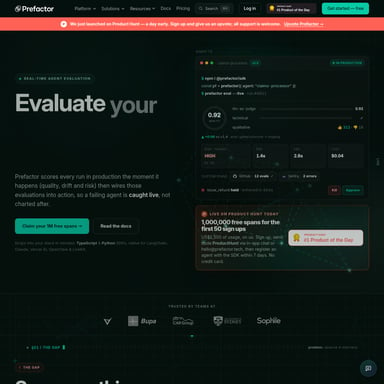
Sercem Mellum2 jest architektura Mixture-of-Experts (MoE). Pozwala ona na osiągnięcie ultra-niskich opóźnień (latency) i wysokiej przepustowości (throughput). W praktyce oznacza to, że Mellum potrafi działać nawet dwa razy szybciej niż inne modele o podobnej skali, wprowadzając zaawansowane możliwości MoE do mniejszej klasy modeli.
2. Optymalizacja pod kątem pracy z kodem
Mellum nie jest tylko narzędziem do prostego uzupełniania linii kodu. Model ten głęboko rozumie strukturę kodu, kontekst projektu oraz intencje programisty. Dzięki temu wspiera on szeroki zakres zadań – od generowania fragmentów oprogramowania po skomplikowane analizy logiczne.
3. Wysoka wydajność przy niższych kosztach
Dzięki mniejszej liczbie aktywnych parametrów na każde żądanie oraz efektywnemu wykorzystaniu mocy obliczeniowej, Mellum pozwala na zmniejszenie kosztów inferencji o połowę przy zachowaniu bardzo wysokiej jakości generowanego kodu. To idealne rozwiązanie dla firm, które chcą skalować swoje rozwiązania AI bez drastycznego zwiększania wydatków na infrastrukturę.
4. Niezawodność i przejrzystość
Modele Mellum są trenowane na transparentnych danych i optymalizowane pod kątem spójności wyników. Daje to użytkownikom pewność co do niezawodności generowanych treści oraz pozwala na łatwiejsze dostosowanie modelu do specyficznych potrzeb projektu.
Rodziny modeli Mellum
JetBrains oferuje różne warianty modeli, aby dopasować się do konkretnych wymagań systemowych:
- Mellum2: Najlepszy wybór dla systemów wymagających niskiej latencji i najwyższej wydajności. Jest to otwarty model 12B MoE, łączący potężne możliwości językowe z wyjątkową sprawnością w czasie rzeczywistym.
- Mellum1: Optymalny do wydajnego generowania kodu wysokiej jakości. Skupia się na szerokim zrozumieniu kodu w wielu językach programowania, co czyni go niezastąpionym narzędziem przy autouzupełnianiu i analizie składniowej.
Zastosowania Mellum (Use Case)
Wszechstronność Mellum pozwala na jego wykorzystanie w wielu zaawansowanych scenariuszach technologicznych:
"Mellum został stworzony, ponieważ nie każde zadanie wymaga największych i najbardziej złożonych modeli. Skupienie się na wydajności i kosztach pozwala na budowanie systemów gotowych do produkcji."
- Inteligentne trasowanie zadań AI: Analiza przychodzących promptów i wybór odpowiedniego modelu dla konkretnego zadania, co pozwala na optymalizację czasu odpowiedzi.
- Niskolatencyjne potoki RAG (Retrieval-Augmented Generation): Szybkie pobieranie istotnych informacji i ich streszczanie przez Mellum, co zapewnia błyskawiczne działanie systemów Q&A.
- Wsparcie dla sub-agentów w złożonych workflow: Rozbicie potoków agentowych na mniejsze kroki (planowanie, walidacja, zbieranie kontekstu) i wykorzystanie Mellum do szybkich, wyspecjalizowanych zadań.
- Lokalne i prywatne instancje AI: Możliwość wdrożenia Mellum lokalnie lub na własnych serwerach (self-hosted) gwarantuje pełną kontrolę nad kodem i danymi, co jest kluczowe dla zachowania prywatności i suwerenności cyfrowej.
Jak zacząć korzystać z Mellum?
Aby rozpocząć pracę z Mellum, użytkownicy mogą wybierać między wdrożeniem w chmurze a instalacją lokalną. Dzięki otwartej naturze modelu (open-source), programiści mają pełną kontrolę nad infrastrukturą i mogą swobodnie dostosowywać (fine-tune) model do swoich unikalnych potrzeb.
- Wybierz model: Zdecyduj się na Mellum2 dla najwyższej szybkości lub Mellum1 dla klasycznego wsparcia kodowania.
- Określ środowisko: Wdróż model lokalnie, aby zachować najwyższy poziom bezpieczeństwa, lub skorzystaj z chmury dla łatwej skalowalności.
- Zintegruj z workflow: Wykorzystaj Mellum w swoich potokach RAG, agentach AI lub jako silnik do uzupełniania kodu.
FAQ – Najczęściej zadawane pytania
Czym jest Mellum? Mellum to rodzina szybkich modeli językowych od JetBrains, zoptymalizowana pod kątem programowania i niskiej latencji.
Czym różni się Mellum2 od poprzednich wersji? Mellum2 to model 12B MoE (Mixture-of-Experts), który oferuje znacznie wyższą wydajność i dwukrotnie szybszą inferencję niż porównywalne modele.
Dlaczego nie używać dużych modeli, takich jak GPT? Nie każde zadanie wymaga ogromnych zasobów. Mellum oferuje lepszy stosunek wydajności do kosztów i znacznie niższe opóźnienia w specyficznych zadaniach programistycznych.
Jak trenowany jest model Mellum2? Model jest trenowany na transparentnych danych z naciskiem na spójność i niezawodność w realnych scenariuszach deweloperskich.
Jak Mellum radzi sobie z wydajnością? Dzięki architekturze MoE, model aktywuje tylko część parametrów dla każdego zapytania, co przekłada się na błyskawiczne czasy odpowiedzi i wysoką przepustowość.
Co sprawia, że Mellum jest efektywny kosztowo? Mniejsze zużycie zasobów obliczeniowych na każde zapytanie pozwala obniżyć koszty inferencji o około 50% w porównaniu do standardowych modeli.
Czy Mellum jest modelem otwartoźródłowym (open-source)? Tak, Mellum to otwarty model LLM, co pozwala na jego swobodne wdrażanie, modyfikowanie i hostowanie we własnej infrastrukturze.
Jakie języki programowania są obsługiwane? Mellum został zbudowany w celu szerokiego zrozumienia kodu w wielu popularnych językach programowania wykorzystywanych w nowoczesnym software developmentcie.