Mellum by JetBrains
Mellum von JetBrains: Hochleistungsfähige Open-Source LLMs für ultra-niedrige Latenz und effiziente Code-Generierung.
Entdecken Sie Mellum, die Familie quelloffener Sprachmodelle von JetBrains. Optimiert für reale Programmieraufgaben, bietet Mellum2 mit seiner 12B-Parameter Mixture-of-Experts-Architektur extrem niedrige Latenzzeiten und hohe Effizienz. Ideal für lokale Bereitstellung, RAG-Pipelines und KI-Agenten.
2026-06-22
--K

Mellum by JetBrains Produktinformationen
JetBrains Mellum: Die neue Ära der Open-Source LLMs für Performance und Effizienz
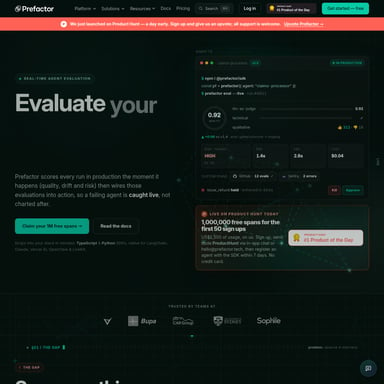
In der dynamischen Welt der Softwareentwicklung ist Geschwindigkeit nicht nur ein Luxus, sondern eine Notwendigkeit. Mit Mellum präsentiert JetBrains eine Familie von schnellen Sprachmodellen, die speziell dafür entwickelt wurden, die Lücken zwischen komplexer KI-Funktionalität und realer Leistung zu schließen. Mellum ist ein quelloffenes Large Language Model (LLM), das für moderne Entwicklungs-Workflows optimiert wurde, bei denen Latenz und Durchsatz die entscheidenden Faktoren sind.
Das Flaggschiff der Serie, Mellum2, setzt neue Maßstäbe für ultra-niedrige Latenzzeiten und Hochleistungs-Inferenz. Während herkömmliche Modelle oft an hohen Rechenanforderungen scheitern, bietet Mellum eine effiziente Alternative, die speziell auf die Bedürfnisse von KI/ML-Ingenieuren und Forschern zugeschnitten ist. Ob für die Code-Vervollständigung oder komplexe Programmieraufgaben – Mellum liefert Ergebnisse in Echtzeit.
Was ist Mellum?
Mellum ist eine von JetBrains entwickelte Familie quelloffener Sprachmodelle. Es handelt sich dabei um spezialisierte KI-Lösungen, die über die reine Code-Generierung hinausgehen. Das Ziel von Mellum ist es, Entwicklern ein Werkzeug an die Hand zu geben, das Code, Kontext und die Absicht hinter Programmieraufgaben versteht.
Die Modellfamilie umfasst verschiedene Varianten wie Mellum1 und Mellum2. Während Mellum1 als spezialisiertes Coding-Modell für breites Code-Verständnis fungiert, ist Mellum2 als 12B-Parameter-Modell mit einer Mixture-of-Experts (MoE) Architektur konzipiert. Diese Architektur erlaubt es Mellum, Aufgaben mit einer Geschwindigkeit zu bearbeiten, die oft doppelt so hoch ist wie bei Modellen vergleichbarer Größe. JetBrains Mellum ist somit die Antwort auf die Frage, wie man leistungsstarke KI-Unterstützung direkt in den produktiven Workflow integriert, ohne Kompromisse bei der Geschwindigkeit einzugehen.
Die herausragenden Features von Mellum
Die Entwicklung von Mellum basierte auf dem Grundsatz, dass nicht jede Aufgabe das größte oder komplexeste Modell benötigt. Stattdessen konzentriert sich Mellum auf das, was in der Produktion wirklich zählt.
Ultra-fast by Design: Die MoE-Architektur
Ein zentrales Merkmal von Mellum2 ist die Mixture-of-Experts (MoE) Architektur. Diese Technologie ermöglicht es dem Modell, für jede Anfrage nur einen Teil seiner Parameter zu aktivieren. Das Ergebnis ist eine ultra-niedrige Latenz und ein außergewöhnlich hoher Durchsatz. In der Praxis bedeutet das, dass Mellum oft doppelt so schnell agiert wie herkömmliche Modelle derselben Klasse und damit MoE-Fähigkeiten in einen wesentlich effizienteren Rahmen bringt.
Hohe Performance bei geringeren Kosten
Mit Mellum lässt sich eine hohe Coding-Qualität erreichen, während die Inferenzkosten halbiert werden. Durch die effiziente Nutzung der Rechenressourcen und weniger aktive Parameter pro Anfrage bietet Mellum ein unschlagbares Preis-Leistungs-Verhältnis für Unternehmen, die KI-Workloads skalieren möchten.
Flexibilität und volle Kontrolle
JetBrains legt großen Wert auf Transparenz. Mellum wurde auf transparenten Daten trainiert und ist für Konsistenz ausgerichtet. Ein entscheidender Vorteil ist die Flexibilität: Mellum kann sowohl lokal als auch in der Cloud bereitgestellt werden. Dies gibt Teams die volle Kontrolle über ihre Performance, den Datenschutz und die gesamte Infrastruktur.
Umfassendes Verständnis von Code und Kontext
Mellum ist nicht nur ein Werkzeug zur Code-Vervollständigung. Es versteht natürliche Sprache ebenso wie komplexe Programmierlogik. Diese Vielseitigkeit macht es zum idealen Begleiter für KI-Workflows, die über das reine Schreiben von Codezeilen hinausgehen.
Mellum Modelle im Überblick
Innerhalb der Mellum-Familie gibt es spezialisierte Versionen, um unterschiedlichen Anforderungen gerecht zu werden:
- Mellum2: Dieses Modell verfügt über 12 Milliarden Parameter und nutzt die Mixture-of-Experts Architektur. Es ist die beste Wahl für Szenarien, die eine extrem niedrige Latenz und Hochleistungs-Inferenz erfordern. Es kombiniert starke Sprach- und Coding-Fähigkeiten mit maximaler Effizienz.
- Mellum1: Ein spezialisiertes Open-Source-Modell für die Code-Generierung. Es bietet ein breites Verständnis über mehrere Programmiersprachen hinweg und ist auf eine qualitativ hochwertige Vervollständigung ausgelegt.
Use Case: Wo Mellum seine Stärken ausspielt
Mellum wurde für den Einsatz in realen Systemen entwickelt. Hier sind einige der primären Einsatzszenarien:
1. Routing und Orchestrierung von KI-Workloads
Nutzen Sie Mellum, um eingehende Prompts zu analysieren und intelligent an das richtige Modell weiterzuleiten. Durch dieses Routing können Aufgaben basierend auf ihren Anforderungen effizient verteilt werden, was die Gesamtsystemgeschwindigkeit erhöht.
2. RAG-Pipelines mit niedriger Latenz
In Retrieval-Augmented Generation (RAG) Systemen ist Geschwindigkeit entscheidend. Mellum kann relevante Informationen blitzschnell zusammenfassen und Antworten generieren, wodurch Question-Answering-Systeme reaktionsschnell bleiben.
3. Unterstützung schneller Sub-Agenten
In komplexen Agenten-Workflows können Sie Pipelines in einzelne Schritte wie Planung, Kontext-Sammlung und Validierung unterteilen. Anstatt ein einzelnes riesiges Modell zu verwenden, übernimmt Mellum als schneller, spezialisierter Sub-Agent diese Teilaufgaben.
4. Private und lokale KI-Nutzung
Für Unternehmen, die Wert auf Souveränität legen, ermöglicht Mellum eine vollständig private Nutzung. Durch die lokale oder selbst gehostete Bereitstellung bleiben Code und Daten unter Ihrer eigenen Kontrolle.
FAQ – Häufig gestellte Fragen zu Mellum
Was ist Mellum? Mellum ist eine Familie von schnellen Sprachmodellen von JetBrains, die für reale Entwicklungsaufgaben optimiert sind, bei denen es auf Geschwindigkeit und Leistung ankommt.
Wie unterscheidet sich die neueste Mellum-Version von den vorherigen? Die neueste Version, Mellum2, nutzt eine Mixture-of-Experts (MoE) Architektur mit 12B Parametern, um eine noch geringere Latenz und höhere Effizienz im Vergleich zu früheren Modellen zu erreichen.
Warum nicht einfach ein großes Modell wie GPT verwenden? Nicht jede Aufgabe erfordert die Komplexität eines riesigen Modells. Mellum bietet eine optimierte Performance und deutlich geringere Kosten bei spezialisierten Aufgaben wie Code-Vervollständigung und RAG-Pipelines.
Ist Mellum Open-Source? Ja, Mellum ist ein quelloffenes LLM, das von JetBrains entwickelt wurde, um Transparenz und Flexibilität für Entwickler zu gewährleisten.
Wie schneidet Mellum in Sachen Performance ab? Dank der MoE-Architektur erreicht Mellum2 eine extrem niedrige Latenz und einen Durchsatz, der oft doppelt so hoch ist wie bei vergleichbaren Modellen.
Was macht Mellum kosteneffizient? Durch die Nutzung von weniger aktiven Parametern pro Anfrage und eine effiziente Rechenausnutzung halbiert Mellum die Inferenzkosten bei gleichbleibend hoher Qualität.
Welche Sprachen werden unterstützt? Mellum wurde für ein breites Spektrum an Programmiersprachen und natürlicher Sprache trainiert, um vielseitige Entwicklungs-Workflows zu unterstützen.
Mellum von JetBrains ist die ideale Lösung für Teams, die von der reinen Experimentierphase in die produktive KI-Entwicklung übergehen wollen. Mit seinem Fokus auf Latenz, Kosten und Offenheit bietet es die perfekte Basis für moderne, KI-gestützte Systeme.