Mellum by JetBrains
Mellum от JetBrains: Высокопроизводительная Open-Source LLM для инференса с ультранизкой задержкой
Mellum — это семейство открытых языковых моделей от JetBrains, оптимизированных для реальных рабочих процессов разработки. Узнайте о Mellum2, 12B MoE модели, обеспечивающей двукратный прирост скорости и снижение стоимости инференса на 50%.
2026-06-22
--K

Mellum by JetBrains Информация о продукте
Mellum от JetBrains: Высокопроизводительная Open-Source LLM для Разработки
В современном мире искусственного интеллекта скорость и эффективность имеют решающее значение. Компания JetBrains представляет Mellum — семейство быстрых языковых моделей с открытым исходным кодом, разработанных специально для тех, кто ценит производительность. В основе Mellum лежит стремление создать инструменты, которые идеально вписываются в реальные рабочие процессы разработки, обеспечивая ультранизкую задержку и исключительное качество кода.
Что такое Mellum?
Mellum — это не просто очередная языковая модель. Это специализированное семейство LLM от JetBrains, созданное для решения задач, где критически важна скорость отклика. Mellum включает в себя модели следующего поколения, такие как Mellum2, которые оптимизированы для высокопроизводительного инференса.
Проект Mellum был запущен, потому что далеко не каждая задача требует использования самых ресурсоемких и сложных моделей. Сосредоточив внимание на производительности, задержках и стоимости, JetBrains создали Mellum для разработчиков и команд, которые переходят от стадии экспериментов к промышленной эксплуатации ИИ-решений.
Семейство моделей Mellum
На данный момент в семейство входят две основные модели, каждая из которых оптимизирована под конкретные нужды:
- Mellum2: Флагманская модель с 12 миллиардами параметров (12B). Она использует архитектуру Mixture-of-Experts (MoE) и предназначена для рабочих процессов в режиме реального времени. Mellum2 сочетает в себе мощные возможности понимания кода и естественного языка с исключительной эффективностью.
- Mellum1: Оптимизированная модель для генерации кода. Она обеспечивает глубокое понимание контекста и автодополнение кода на множестве языков программирования.
Ключевые особенности Mellum
Модели Mellum выделяются на фоне конкурентов благодаря ряду технических преимуществ, которые делают их идеальным выбором для современных AI/ML инженеров.
Ультрабыстрая работа по дизайну
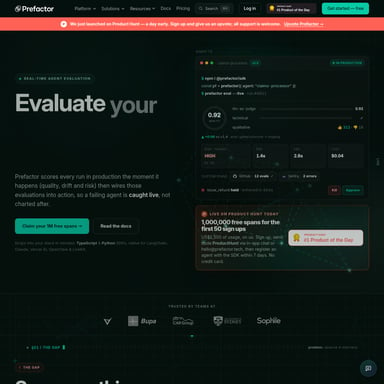
Благодаря архитектуре Mixture-of-Experts (MoE), Mellum обеспечивает ультранизкую задержку при инференсе и высокую пропускную способность. На практике это означает, что модели Mellum часто работают в два раза быстрее, чем аналогичные модели того же размера. JetBrains удалось внедрить возможности MoE в класс значительно более компактных моделей, что является прорывом для индустрии.
Высокая производительность при низких затратах
Mellum не только быстрее, но и экономичнее. Использование Mellum позволяет снизить затраты на инференс вдвое. Это достигается за счет уменьшения количества активных параметров, задействованных при обработке каждого конкретного запроса, и максимально эффективного использования вычислительных мощностей.
Глубокое понимание кода и контекста
Разработанный JetBrains, Mellum понимает не только синтаксис кода, но и контекст, а также намерения разработчика. Модель выходит за рамки простого автодополнения, поддерживая как задачи программирования, так и работу с естественным языком.
Надежность и прозрачность
Mellum обучается на прозрачных данных и настраивается для обеспечения максимальной согласованности ответов. Это делает модель предсказуемым инструментом в руках профессионалов.
Сферы применения (Use Case)
Гибкость и скорость Mellum позволяют использовать его в самых разных сценариях — от простых скриптов до сложных агентских систем.
Оркестрация рабочих нагрузок ИИ
Mellum может выступать в роли интеллектуального роутера. Он анализирует входящие промпты и выбирает подходящую модель для каждой конкретной задачи, обеспечивая быструю и эффективную маршрутизацию.
Конвейеры RAG с низкой задержкой
В системах Retrieval-Augmented Generation (RAG) Mellum мгновенно извлекает релевантную информацию и формирует краткие, точные ответы. Это позволяет поддерживать высокую отзывчивость вопросно-ответных систем.
Быстрые субагенты в сложных рабочих процессах
Вместо того чтобы полагаться на одну тяжелую модель, вы можете разбить конвейер ИИ-агентов на этапы (планирование, сбор контекста, валидация) и поручить Mellum выполнение быстрых специализированных задач.
Локальное и приватное использование ИИ
Для компаний, заботящихся о суверенитете данных, Mellum предлагает возможность локального развертывания. Вы сохраняете полный контроль над своим кодом и инфраструктурой, обеспечивая максимальную приватность.
Как начать работу с Mellum
JetBrains спроектировали Mellum таким образом, чтобы его было легко интегрировать в существующую инфраструктуру. Вы можете выбрать наиболее удобный способ развертывания:
- Локальное использование: Запускайте Mellum на собственном оборудовании для обеспечения полной конфиденциальности.
- Облачное развертывание: Используйте гибкость облачных вычислений для масштабирования ваших ИИ-сервисов.
- Тонкая настройка (Fine-tuning): Адаптируйте Mellum под специфику вашего проекта или внутренние стандарты кодирования компании.
Для начала работы достаточно выбрать интересующую модель в списке доступных продуктов JetBrains и следовать инструкциям по установке.
Примечание по безопасности: При использовании веб-ресурсов JetBrains могут использоваться файлы cookie и запись IP-адресов для обеспечения доступности и безопасности. Вы всегда можете настроить параметры сбора данных в своем браузере или через меню управления настройками.
Часто задаваемые вопросы (FAQ)
Что такое Mellum? Это семейство быстрых языковых моделей от JetBrains, оптимизированных для задач программирования и высокопроизводительного инференса с открытым исходным кодом.
Чем Mellum2 отличается от предыдущих версий? Mellum2 — это модель следующего поколения с 12 млрд параметров и архитектурой Mixture-of-Experts, ориентированная на ультранизкую задержку в реальных рабочих процессах.
Почему стоит использовать Mellum вместо огромных моделей вроде GPT? Mellum обеспечивает сопоставимое качество в задачах кодинга при значительно более высокой скорости (в 2 раза быстрее) и меньшей стоимости (в 2 раза дешевле), позволяя избежать избыточности.
Как обучается Mellum? Модели обучаются на прозрачных данных с акцентом на консистентность и надежность результатов, что критично для профессиональной разработки.
Насколько производителен Mellum? Благодаря MoE-архитектуре, Mellum демонстрирует высокую пропускную способность и является одной из самых быстрых моделей в своем классе.
За счет чего Mellum экономически эффективен? Экономия достигается благодаря эффективному использованию вычислительных ресурсов и меньшему числу активных параметров на запрос.
Какие языки поддерживаются? Mellum поддерживает широкий спектр языков программирования, обеспечивая качественное понимание и генерацию кода.
Является ли Mellum открытым исходным кодом? Да, Mellum — это open-source решение, что дает разработчикам полный контроль над его использованием и развертыванием.