Mellum by JetBrains
Mellum de JetBrains: Modelos LLM de código abierto con ultra baja latencia y alto rendimiento para desarrolladores
Mellum es una familia de modelos de lenguaje rápidos de JetBrains, optimizados para flujos de trabajo de desarrollo real. Incluye Mellum2, un modelo de 12B parámetros con arquitectura Mixture-of-Experts que garantiza inferencia de alta velocidad y menores costos.
2026-06-22
--K

Mellum by JetBrains Información del producto
Mellum: Los Modelos de Lenguaje de Alto Rendimiento de JetBrains
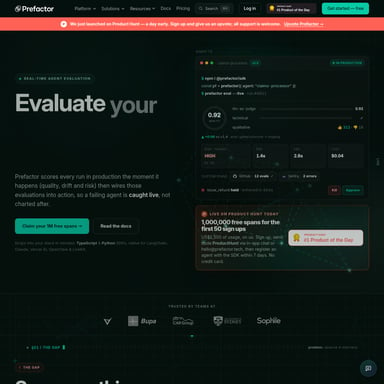
En el panorama actual de la inteligencia artificial, la eficiencia y la velocidad son factores determinantes para el éxito de cualquier flujo de trabajo de desarrollo. JetBrains presenta Mellum, una familia de modelos de lenguaje rápidos que incluye una generación avanzada diseñada específicamente para ofrecer una inferencia de ultra baja latencia y alto rendimiento. Mellum se posiciona como el LLM de código abierto optimizado para los entornos de desarrollo del mundo real, donde cada milisegundo cuenta.
¿Qué es Mellum?
Mellum es una familia de modelos de lenguaje de código abierto desarrollados por JetBrains. Este proyecto surge de la necesidad de contar con herramientas de IA que no solo comprendan el código, sino que también se integren perfectamente en los flujos de trabajo diarios de los desarrolladores y equipos de ingeniería. A diferencia de otros modelos generales, Mellum ha sido construido pensando en el rendimiento, la latencia y el costo.
El ecosistema Mellum incluye modelos diseñados para tareas específicas, como la generación de código de alta calidad y la inferencia rápida en tiempo real. Al ser una solución de código abierto, Mellum ofrece a los ingenieros de AI/ML e investigadores un control total sobre su infraestructura, permitiendo despliegues tanto en la nube como de forma local.
Características Principales de Mellum
El éxito de Mellum radica en su diseño técnico y su enfoque en la utilidad práctica. A continuación, se detallan las características que hacen de Mellum una opción líder para el desarrollo moderno:
Arquitectura de Mezcla de Expertos (Mixture-of-Experts - MoE)
La arquitectura Mixture-of-Experts (MoE) es el corazón de Mellum, especialmente en su versión Mellum2. Este diseño permite ofrecer una latencia ultra baja y un alto rendimiento (throughput). Lo que hace destacar a Mellum es su capacidad para llevar las ventajas de MoE a una clase de modelos mucho más pequeña, logrando velocidades que suelen ser el doble de rápidas que otros modelos de tamaño similar.
Optimización para Flujos de Trabajo Reales
Mellum no se limita a la simple finalización de código. Ha sido entrenado para comprender el código, el contexto y la intención del desarrollador. Esto le permite ampliar sus capacidades más allá de la programación pura, brindando soporte tanto en tareas de lenguaje natural como en tareas de programación complejas.
Rendimiento Superior con Menor Costo
Una de las mayores ventajas de Mellum es su eficiencia económica. Mellum logra una alta calidad de codificación mientras reduce a la mitad los costos de inferencia. Esto es posible gracias a que utiliza menos parámetros activos por solicitud y maximiza la utilización del cómputo de manera eficiente.
Flexibilidad y Confiabilidad
Entrenado con datos transparentes y alineado para mantener la consistencia, Mellum es un modelo altamente fiable. Su naturaleza flexible permite que sea ajustado (fine-tuned) y desplegado de acuerdo con las necesidades específicas de privacidad y rendimiento de cada empresa, ya sea en servidores locales o en infraestructuras cloud.
Modelos Mellum Disponibles
JetBrains ha desarrollado diferentes variantes de Mellum para adaptarse a diversas necesidades de computación y desarrollo:
Mellum2
Es el modelo ideal para quienes buscan la máxima velocidad. Mellum2 es un modelo de código abierto de 12 mil millones de parámetros (12B) basado en la arquitectura MoE. Está diseñado para flujos de trabajo en tiempo real, combinando una gran capacidad de lenguaje y codificación con una eficiencia excepcional.
Mellum1
Este modelo está enfocado específicamente en la generación de código de alta calidad. Mellum1 es un modelo de codificación de código abierto construido para ofrecer una comprensión amplia del código y completar tareas de programación en múltiples lenguajes.
Casos de Uso de Mellum
Mellum ha sido diseñado para tener un impacto real en los sistemas de producción. Algunos de sus casos de uso más destacados incluyen:
- Enrutamiento y Orquestación de Cargas de Trabajo de IA: Mellum puede analizar los prompts entrantes y seleccionar el modelo adecuado para cada tarea, actuando como un orquestador inteligente que optimiza los requisitos de velocidad y precisión.
- Pipelines de RAG (Generación Aumentada por Recuperación) de Baja Latencia: Permite recuperar información relevante rápidamente para resumir y generar respuestas en sistemas de preguntas y respuestas, manteniendo una alta capacidad de respuesta.
- Agentes Secundarios Rápidos en Flujos Complejos: En pipelines de agentes complejos, Mellum puede encargarse de pasos especializados como la recopilación de contexto, la planificación y la validación, evitando la dependencia total de un único modelo grande y lento.
- Uso de IA Local y Privada: Mellum facilita el mantenimiento del código y los datos bajo control total del usuario mediante el despliegue local o auto-hospedado, ideal para casos de uso de IA soberana y privada.
Preguntas Frecuentes (FAQ)
¿Qué es Mellum?
Es una familia de modelos de lenguaje rápidos y de código abierto creados por JetBrains, optimizados para ofrecer alto rendimiento y baja latencia en tareas de desarrollo y programación.
¿En qué se diferencia la última versión de Mellum de las anteriores?
La versión más reciente, Mellum2, introduce una arquitectura de mezcla de expertos (MoE) con 12B de parámetros, optimizada para inferencia en tiempo real y una eficiencia significativamente mayor en comparación con modelos estándar.
¿Por qué no usar simplemente un modelo grande como GPT?
Porque no todas las tareas requieren la complejidad de los modelos más grandes. Mellum se enfoca en el rendimiento, la latencia y el costo, siendo ideal para equipos que pasan de la fase de experimentación a la de producción real.
¿Cómo se entrena Mellum?
Mellum se entrena utilizando datos transparentes y se alinea cuidadosamente para garantizar la consistencia en sus respuestas y su comportamiento en entornos de desarrollo.
¿Cómo es el rendimiento de Mellum?
Ofrece una inferencia de ultra baja latencia y un rendimiento de procesamiento que a menudo duplica la velocidad de modelos de tamaño similar, manteniendo una alta calidad en la generación de código.
¿Qué hace que Mellum sea eficiente en costos?
Su eficiencia proviene de la arquitectura MoE, que utiliza menos parámetros activos por cada solicitud, lo que permite reducir los costos de inferencia a la mitad sin sacrificar la calidad.
¿Qué lenguajes son compatibles?
Mellum1 y Mellum2 ofrecen soporte para múltiples lenguajes de programación, proporcionando una comprensión amplia para la finalización y generación de código.
¿Es Mellum de código abierto?
Sí, Mellum es un LLM de código abierto, lo que permite a los desarrolladores y empresas desplegarlo, ajustarlo y controlarlo según sus propias necesidades de infraestructura.