Fish Audio S2
Fish Audio S2:开源且极具表现力的语音 AI 文本转语音与声音克隆模型
Fish Audio S2 是一款革命性的开源语音 AI 模型,支持文本转语音 (TTS)、声音克隆和语音转文字。它具备超低延迟、多语言支持及强大的情感控制能力,能通过自然语言指令实现如欢笑、耳语、叹气等细腻表达。依托 1000 万小时音频数据训练及 Dual-AR 架构,S2 Pro 提供极致的真实感与 150ms 以内的响应速度,是开发者构建实时对话 AI、播客和虚拟角色的首选方案。
2026-03-12
--K

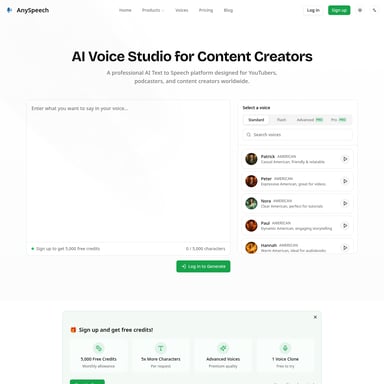
Fish Audio S2 产品信息
Fish Audio S2:定义未来语音 AI 的超强表现力开源模型
在人工智能语音技术飞速发展的今天,Fish Audio S2 作为一款兼具超高性能与开放性的语音 AI 模型脱颖而出。它不仅是简单的文本转语音 (Text to Speech) 工具,更是目前最具表现力的开源语音 AI 之一,能够生成令人难以置信的真实语音,广泛应用于声音克隆 (Voice Cloning)、语音转文字 (Speech to Text) 以及实时对话场景。
什么是 Fish Audio S2? (What's Fish Audio S2)
Fish Audio S2 是由 Fish Audio 开发的新一代语音 AI 模型,旨在打破传统合成语音的机械感。作为一款完全开源的模型,Fish Audio S2 提供了从推理代码到模型权重的全方位支持。它采用了先进的 Dual-Autoregressive (Dual-AR) 架构:
- 4B 参数的 Slow AR:负责处理语义预测,确保语音内容的准确性。
- 400M 参数的 Fast AR:负责捕捉声音细节,还原人类语音的细微质感。
该模型基于超过 1000 万小时的多语言音频数据进行训练,支持超过 80 种语言。无论是日常对话中的清嗓子、笑声,还是带有强烈情感色彩的叹气、强调,Fish Audio S2 都能完美呈现。
Fish Audio S2 的核心功能 (Features)
1. 超低延迟 (Ultra-Low Latency)
Fish Audio S2 的响应时间低于 150ms。这种极速性能使其成为实时对话 AI、直播配音以及交互式语音应用的理想选择,实现了无需等待的流畅交互体验。
2. 开放域控制与多角色对话 (Open Domain Control & Multi-Speaker)
这是 Fish Audio S2 最显著的优势之一。用户可以通过简单的自然语言文本指令,精细化地控制语音的情感和副语言特征:
- 情感表达:通过
[giggles](咯咯笑)、[whispering](耳语)、[sighing](叹息) 等标签实时注入情感。 - 细粒度控制:支持超过 15,000 个独特标签,如
[emphasis](强调)、[flirty](调情)、[excited](兴奋) 等。 - 无缝切换:在单次生成任务中即可实现多个说话人之间的自然转换,非常适合制作广播剧或对话式播客。
3. 完全开源与灵活部署 (Fully Open-Source)
Fish Audio S2 的推理代码和模型权重全部开源。开发者可以在自己的基础设施上运行 S2,根据特定数据进行微调,完全不受供应商锁定 (Vendor Lock-in) 的限制。
4. 卓越的并发性能
利用 SGLang 推理引擎,S2 Pro 在 NVIDIA H200 GPU 上实现了 0.195 的实时因子 (RTF),每秒可吞吐超过 3,000 个声学 Token,支持连续批处理和前缀缓存优化。
应用场景 (Use Case)
- 开发者 (Developers):通过 Fish Audio S2 API 将极具表现力的语音功能集成到应用中。
- 内容创作者:利用声音克隆技术为视频、有声书或动画提供极富情感的配音。
- 客服与虚拟助手:打造具备 150ms 以内超低延迟的实时对话机器人。
- 教育与辅助工具:将教材转换为 80 多种语言的高质量语音,支持语言学习。
如何使用 Fish Audio S2 (How to Use)
开发者可以非常简便地通过 Python 调用 Fish Audio S2 API 来生成栩栩如生的语音。以下是一个简单的示例代码:
from fishaudio import FishAudio
from fishaudio.utils import save
# 使用您的 API 密钥初始化客户端
client = FishAudio(api_key="your_api_key_here")
# 生成极具表现力的语音
audio = client.tts.convert(
text="Fish Audio S2 is the best voice AI model.",
model="s2-pro"
)
# 保存音频文件
save(audio, "welcome.mp3")
此外,用户还可以直接在平台上输入带有标签的文本,例如:
[calm] 欢迎来到我们的放松水疗中心 [pause] [whispering] 后面有零食。
常见问题解答 (FAQ)
Q: Fish Audio S2 Pro 支持哪些语言?
A: S2 Pro 支持 80 多种语言。其中第一梯队(质量最高)包括中文、英语和日语;第二梯队包括韩语、西班牙语、俄语、德语等。此外还支持泰语、越南语、印地语等多种语言。
Q: 什么是“细粒度行内控制”?
A: 这意味着您可以通过在文本中插入类似 [whisper in small voice] 或 [professional broadcast tone] 的自然语言标签,精准控制每一个词的情感和语调,而不仅限于预设的几种模式。
Q: Fish Audio S2 的开源许可协议是什么?
A: S2 Pro 采用 Fish Audio Research License。研究和非商业用途免费;商业用途需要联系 [email protected] 获取单独的授权。
Q: 它在硬件上的表现如何?
A: S2 Pro 经过高度优化,在单张 NVIDIA H200 GPU 上,首个音频片段生成时间 (TTFA) 仅约为 100ms,吞吐量极高。
立即探索 Fish Audio S2,体验前所未有的 AI 语音表现力!