Fish Audio S2
Fish Audio S2: 80ヶ国語以上に対応した、最も表情豊かなオープンソース音声AI
Fish Audio S2は、感情制御、音声合成、音声複製、文字起こしを網羅する次世代の音声AIです。1,000万時間以上の学習データを基に、笑い、囁き、ため息などの微細な感情表現を自然言語で制御可能。150ms以下の超低遅延とオープンソースの柔軟性を兼ね備え、開発者向けAPIも提供。日本語を含む80ヶ国語以上で、これまでにないリアルな音声体験を商用・研究の両面で実現します。
2026-03-12
--K

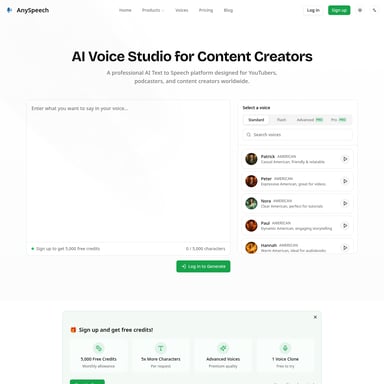
Fish Audio S2 製品情報
Fish Audio S2: 感情豊かな表現を実現する次世代オープンソース音声AI
Fish Audio S2は、これまでに作られた中で最も表現力豊かな音声AIであり、現在はオープンソースとして公開されています。テキストから音声を生成するText to Speech (TTS)、既存の声を再現するVoice Cloning、音声をテキスト化するSpeech to Textなど、音声技術のあらゆるニーズに応える包括的なプラットフォームです。
現在、期間限定の特別オファーとして年間プランが50% OFFで提供されています。この機会に、信じられないほどリアルな音声生成を体験してください。
What's Fish Audio S2?
Fish Audio S2(および上位モデルのFish Audio S2 Pro)は、プロソディ(韻律)と感情をきめ細かく制御できる最先端の音声合成モデルです。1,000万時間以上のオーディオデータと80ヶ国語以上の多言語データを用いてトレーニングされています。
このモデルの最大の特徴は、Dual-Autoregressive (Dual-AR) アーキテクチャにあります。意味予測を行う40億パラメータの「Slow AR」と、音響的な詳細を司る4億パラメータの「Fast AR」を組み合わせることで、人間の生きた声に近い、極めて自然な発話を可能にしました。
Fish Audio S2 の主な特徴
Fish Audio S2が他の音声AIと一線を画す理由は、その表現力、スピード、そして開放性にあります。
1. 超低遅延(Ultra-Low Latency)
応答時間は150ms未満を実現。この圧倒的なスピードにより、リアルタイムの対話型AI、ライブ吹き替え、インタラクティブな音声アプリケーションにおいて、品質を損なうことなくプロダクションレベルのパフォーマンスを発揮します。
2. オープンドメイン制御とマルチスピーカー対応
自然なテキスト指示(タグ)を使用して、感情やパラ言語を自由にコントロールできます。笑い、囁き、ため息など、あらゆる表現要素を追加可能です。
- マルチスピーカー機能: 1つの生成プロセス内で、複数の話者間を自然に切り替えることができます。
3. 完全オープンソース
推論コードとモデルの重みが完全に公開されています。ベンダーロックインを避け、自社のインフラでFish Audio S2を実行したり、独自のデータでファインチューニングしたりすることが可能です。
4. 高度なインライン制御
[whisper](囁き)や[laughing](笑い)といった15,000以上のユニークなタグをサポート。特定の単語レベルで表現をカスタマイズできます。
Fish Audio S2 の活用シーン (Use Case)
Fish Audio S2は、その柔軟性と高品質な音声により、多岐にわたる分野で活用されています。
- スタートアップ・開発者: APIを活用し、独自の音声対話型チャットボットやアプリを構築。
- オーディオブック・ナレーション: 感情豊かな読み上げにより、没入感のあるコンテンツ制作。
- キャラクターボイス: ゲームやエンターテインメントにおける、個性的でリアルな声の演出。
- 多言語展開: 日本語、英語、中国語を含む80ヶ国語以上でのグローバルな音声ソリューション。
- 教育・研究: オープンソースモデルを活用した、高度な音声技術の学術的探求。
How to Use: 開発者向け導入ガイド
Fish Audio S2 APIを使用すれば、わずか数行のコードで80ヶ国語以上の感情豊かな音声を生成できます。
from fishaudio import FishAudio
from fishaudio.utils import save
# APIキーでクライアントを初期化
client = FishAudio(api_key="your_api_key_here")
# 音声を生成(モデルに s2-pro を指定)
audio = client.tts.convert(
text="Fish Audio S2 is the best voice AI model.",
model="s2-pro"
)
# ファイルとして保存
save(audio, "welcome.mp3")
FAQ (よくある質問)
Q: Fish Audio S2 Proとは何ですか?
A: 1,000万時間以上のデータで学習された、プロソディと感情の微細な制御が可能なTTSモデルです。SGLangベースのストリーミングエンジンにより、高速かつ高品質な音声出力を実現しています。
Q: 感情の制御はどのように行いますか?
A: テキスト内に[pause]、[excited]、[whisper in small voice]などの自然言語タグを埋め込むことで、特定の箇所に感情や動作を付加できます。
Q: 対応言語を教えてください。
A: 日本語、英語、中国語(ティア1:最高品質)をはじめ、韓国語、スペイン語、フランス語、ドイツ語など計80ヶ国語以上をサポートしています。
Q: パフォーマンス(速度)はどのくらいですか?
A: NVIDIA H200 GPU 1枚で、Real-Time Factor (RTF) 0.195、最初の音声出力までの時間は約100msです。
Q: ライセンスはどうなっていますか?
A: Fish Audio Research Licenseの下で公開されています。研究および非商用利用は無料ですが、商用利用には別途ライセンス契約が必要です。詳細は [email protected] までお問い合わせください。
Fish Audio S2は、単なる音声合成を超え、人間に寄り添う表現力を提供します。今すぐその圧倒的なリアリティを体験してください。