Fish Audio S2
Fish Audio S2: Najbardziej ekspresyjna sztuczna inteligencja głosowa Open-Source z niskimi opóźnieniami
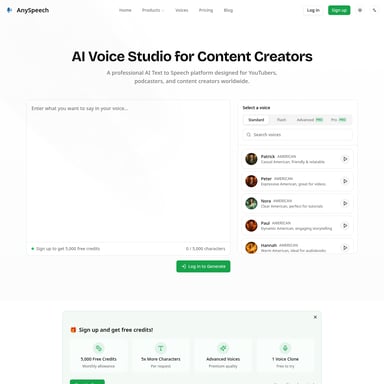
Fish Audio S2 to przełomowy model AI do generowania mowy (Text-to-Speech), który redefiniuje standardy ekspresji i realizmu. Dzięki architekturze Dual-Autoregressive i treningowi na 10 milionach godzin nagrań w ponad 80 językach, model pozwala na precyzyjną kontrolę emocji, pauz i dźwięków paralingwistycznych za pomocą komend tekstowych. Fish Audio S2 oferuje ultra-niskie opóźnienia poniżej 150ms, co czyni go idealnym rozwiązaniem dla chatbotów i dubbingu na żywo. Jako projekt open-source, umożliwia pełną transparentność i integrację bez blokady dostawcy.
2026-03-12
--K

Fish Audio S2 Informacje o produkcie
Fish Audio S2: Najbardziej Ekspresyjna Sztuczna Inteligencja Głosowa AI
W erze cyfrowej komunikacji, realizm i emocje w głosie generowanym komputerowo stają się kluczowym elementem interakcji. Fish Audio S2 to najnowsze osiągnięcie w dziedzinie sztucznej inteligencji, reklamowane jako najbardziej ekspresyjna technologia voice AI, jaka kiedykolwiek powstała. Co więcej, jest to rozwiązanie typu open-source, co otwiera nowe drzwi dla programistów i twórców na całym świecie.
Czym jest Fish Audio S2?
Fish Audio S2 to zaawansowany model Text-to-Speech (TTS), który został zaprojektowany od podstaw, aby dostarczać niebywale realistyczną mowę. To nie tylko prosty syntezator mowy, ale potężne narzędzie oparte na architekturze Dual-Autoregressive (Dual-AR). Składa się on z modelu 4B-parameter Slow AR odpowiedzialnego za przewidywanie semantyczne oraz modelu 400M-parameter Fast AR, który dba o szczegóły akustyczne.
Projekt Fish Audio S2 wyróżnia się na tle konkurencji możliwością niemal nieograniczonej kontroli nad ekspresją. Dzięki treningowi na ponad 10 milionach godzin danych audio w ponad 80 językach, system potrafi naśladować ludzkie westchnienia, śmiech, szept, a nawet specyficzne akcenty i pauzy, które sprawiają, że głos brzmi naturalnie, a nie mechanicznie.
Kluczowe cechy Fish Audio S2
Technologia stoi za sukcesem Fish Audio S2, oferując zestaw unikalnych funkcji, które czynią go liderem w branży:
Ultra-niskie opóźnienia (Ultra-Low Latency)
Czas reakcji poniżej 150ms pozwala na wykorzystanie Fish Audio S2 w aplikacjach działających w czasie rzeczywistym. Jest to idealne rozwiązanie dla interaktywnych asystentów głosowych, systemów konwersacyjnych AI oraz dubbingu na żywo.
Open Domain Control & Multi-Speaker
Model umożliwia płynne przełączanie się między różnymi mówcami w ramach jednej generacji. Co ważniejsze, Fish Audio S2 obsługuje instrukcje w języku naturalnym do kontrolowania emocji i parajęzyka. Możesz dodać do tekstu komendy takie jak [giggles] czy [whispering], aby uzyskać pożądany efekt.
Pełny Open-Source
Zarówno kod wnioskowania (inference), jak i wagi modelu są w pełni otwarte. Oznacza to brak tzw. vendor lock-in – możesz uruchomić Fish Audio S2 na własnej infrastrukturze, dostosować go do swoich danych i swobodnie integrować z własnymi projektami.
Wysoka wydajność streamingowa
Dzięki silnikowi opartemu na SGLang, model osiąga współczynnik Real-Time Factor (RTF) na poziomie 0.195 na procesorach NVIDIA H200. Pozwala to na generowanie ponad 3000 tokenów akustycznych na sekundę.
Zastosowania Fish Audio S2 (Use Case)
Wszechstronność Fish Audio S2 sprawia, że znajduje on zastosowanie w wielu branżach:
- Chatboty konwersacyjne: Tworzenie asystentów, którzy nie tylko odpowiadają merytorycznie, ale też potrafią wyrazić empatię lub poczucie humoru.
- Produkcja audiobooków: Generowanie długich treści z dynamiczną intonacją, szeptem i pauzami, które angażują słuchacza.
- Voiceovers dla twórców wideo: Szybkie tworzenie wysokiej jakości lektora w wielu językach (ponad 80 obsługiwanych języków).
- Gaming: Postacie w grach, które reagują naturalnym głosem na działania gracza.
- Dla programistów: Łatwa integracja poprzez API i możliwość hostowania na własnych serwerach.
Jak używać Fish Audio S2?
Integracja z Fish Audio S2 jest niezwykle prosta dla programistów dzięki bibliotece Python. Poniżej znajduje się przykład, jak wygenerować mowę przy użyciu API:
from fishaudio import FishAudio
from fishaudio.utils import save
# Inicjalizacja kluczem API
client = FishAudio(api_key="twój_klucz_api")
# Generowanie mowy
audio = client.tts.convert(
text="Fish Audio S2 to najlepszy model voice AI.",
model="s2-pro"
)
save(audio, "powitanie.mp3")
Dzięki składni [tag] możesz bezpośrednio w tekście sterować tym, jak model ma wypowiedzieć dane słowa, np. dodając [emphasis] dla podkreślenia ważnych fragmentów lub [sighing] dla wyrażenia rezygnacji.
FAQ - Najczęściej zadawane pytania
Co to jest Fish Audio S2 Pro?
To wiodący model text-to-speech z precyzyjną kontrolą prozodii i emocji. Wykorzystuje architekturę Dual-AR i został przeszkolony na ogromnym zbiorze danych audio, obsługując ponad 80 języków.
Jak działa precyzyjna kontrola inline?
Fish Audio S2 pozwala na osadzanie instrukcji w języku naturalnym bezpośrednio w tekście za pomocą nawiasów kwadratowych. Obsługuje ponad 15 000 unikalnych tagów, takich jak [whisper], [laughing], czy [professional broadcast tone].
Ile języków obsługuje model?
Model wspiera ponad 80 języków. Języki najwyższej jakości (Tier 1) to angielski, japoński i chiński. Tier 2 obejmuje m.in. hiszpański, francuski, niemiecki, rosyjski, a także polski i wiele innych.
Jaka jest licencja Fish Audio S2 Pro?
Model jest udostępniany na licencji Fish Audio Research License. Użytek badawczy i niekomercyjny jest bezpłatny. Zastosowania komercyjne wymagają oddzielnej licencji.
Jakie są wymagania sprzętowe dla najwyższej wydajności?
Model osiąga najlepsze wyniki na kartach graficznych takich jak NVIDIA H200, wykorzystując optymalizacje takie jak Paged KV Cache i ciągłe przetwarzanie wsadowe (continuous batching).