Lightning V3
Lightning TTS V3:专为语音智能体打造的100毫秒超低延迟文本转语音模型
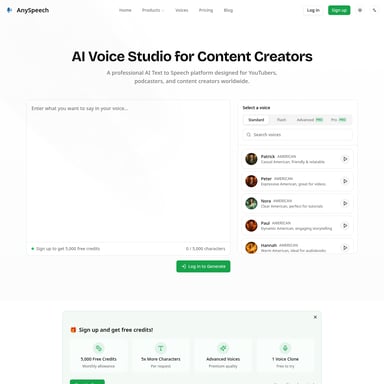
Lightning TTS V3 是由 Smallest.ai 开发的新一代 AI 语音引擎。该模型拥有行业领先的 100ms 超低延迟,支持 15 种语言的自然无缝切换,并能在 10 秒内实现高保真声音克隆。它专为对话式 AI、客户支持、游戏开发和有声读物等场景设计,提供广播级音频输出,具备 SOC 2、HIPAA 等企业级安全认证,是构建实时语音智能体和大规模音频生产的理想选择。
2026-04-04
--K

Lightning V3 产品信息
Lightning TTS V3:专为语音智能体构建的下一代文本转语音技术
在当今 AI 驱动的时代,Lightning TTS V3 重新定义了语音合成的标准。作为一款专门为语音智能体(Voice Agents)打造的文本转语音(Text to Speech)模型,Lightning TTS V3 以其卓越的 100ms 超低延迟和广播级的音频质量,成为了全球顶尖基础设施团队在处理大规模语音任务时的首选方案。
无论是在实时对话、长篇叙事,还是在多语言本地化场景中,Lightning TTS V3 都能展现出如同真人般的自然感与表现力,彻底告别传统 AI 语音的“脚本感”。
什么是 Lightning TTS V3? (What's Lightning TTS V3)
Lightning TTS V3 是由 Smallest.ai 推出的高性能语音合成模型。它不仅仅是一个简单的 TTS 工具,更是一个能够理解语境、自适应不同场景的语音引擎。该模型支持 15 种语言,能够实现中途无缝的语码转换(Code-mixing),并提供 100ms 以内的首包音频延迟(Time-to-first-audio),是构建对话式 AI 和实时交互系统的核心组件。
"Lightning TTS V3 旨在让 AI 听起来像真人,而不是机械的脚本阅读器。"
Lightning TTS V3 的核心功能 (Features)
1. 行业领先的低延迟性能
Lightning TTS V3 在实时性方面表现卓越,可维持 20 个以上并发流,且延迟始终保持在 100ms 以下。这使得它在处理需要即时反馈的语音智能体应用时游刃有余。
2. 多语言与自适应能力
目前支持 15 种语言,包括:
- 欧洲语言:英语、法语、德语、意大利语、葡萄牙语、瑞典语、荷兰语、西班牙语。
- 印度语系:印地语、泰米尔语、泰卢固语、马拉雅拉姆语、卡纳达语、马拉地语、古吉拉特语。
- 模型具备自动语言检测功能,甚至可以在句子中间进行自然的跨语言切换。
3. 秒级高保真声音克隆
无需专业设备,只需上传一段不到 15 秒的音频样本,Lightning TTS V3 即可在 10 秒内生成生产级别的克隆声音。克隆后的声音保留了原始人声的细腻质感与频率特征。
4. 广播级音频质量
提供适用于播客、有声读物和游戏角色的高清晰度输出。它支持多种音频格式输出,包括:
- PCM
- MP3
- WAV
- mulaw
5. 企业级安全与合规
Lightning TTS V3 专为大规模生产环境设计,符合多项国际标准:
- SOC 2 Type II 认证与年度审计
- HIPAA 合规(保护健康信息)
- GDPR 合规
- 99.99% 的正常运行时间 SLA(针对企业客户)
Lightning TTS V3 的应用场景 (Use Case)
Lightning TTS V3 的通用性使其能够适应几乎所有的语音使用场景:
- 语音智能体 (Voice Agents):构建能够进行实时、自然对话的客服机器人。
- 游戏开发 (Gaming):为游戏角色赋予具有情感范围和动态表现力的配音。
- 有声读物 (Audiobooks):长篇叙事具有自然的韵律和节奏感,缓解听觉疲劳。
- 媒体与广告 (Media & Ads):快速生成高质量的片头、广告旁白及整集播客内容。
- 本地化 (Localisation):生成地道的跨国语言语音,助力业务全球化。
- 辅助功能 (Accessibility):为屏幕阅读器和辅助工具提供清晰、优化的语音输出。
- 行业垂直领域:广泛应用于金融(支付 IVR)、医疗(预约提醒)、旅行(预订支持)及电信行业。
常见问题解答 (FAQ)
Lightning V3.1 支持多少种语言?
目前支持 15 种语言,包括英语、西班牙语、印地语和泰米尔语等。我们在欧洲语系和印度语系中拥有极强的覆盖能力。更多语言正在定期添加中。
声音克隆需要多长时间?我需要提供多少音频?
只需不到 15 秒的音频。克隆过程几乎是瞬间完成的(10秒内),且生成的克隆声音可以立即用于任何规模的部署。
Lightning TTS V3 的延迟表现如何?
该模型提供低于 100ms 的首包音频延迟。它是专为实时应用构建的,因此低延迟是其默认特性,无需在质量和速度之间做权衡。
费用如何计算?有免费试用吗?
注册即可获得 $10 的免费额度。此后采取按需付费模式(Pay-as-you-go)。对于需要超大规模并发的企业团队,我们提供定制的进阶方案,请联系销售团队获取详情。
我的数据安全吗?是否会被用于训练模型?
不会。您的数据属于您自己。我们仅出于运营目的记录交互,绝不会利用您的数据来训练我们的模型。您的隐私受到 SOC 2、HIPAA 和 GDPR 标准的严格保护。
我可以控制语音的情感和语速吗?
Lightning V3.1 的语音设计为根据语境自动调整情感和节奏。如果您需要更直接的手动控制,我们的指令模型 V3.2 即将发布,敬请期待。