Fish Audio S2
Fish Audio S2: The Most Expressive Open-Source Voice AI for Realistic Text-to-Speech and Voice Cloning
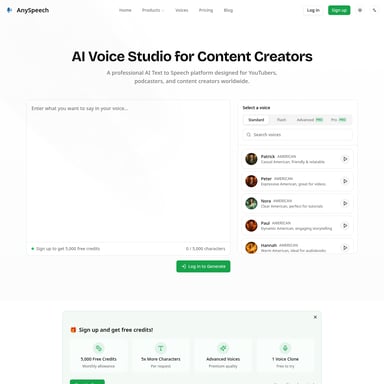
Fish Audio S2 is a revolutionary open-source voice AI model designed for ultra-realistic text-to-speech, speech-to-text, and voice cloning. Featuring a Dual-Autoregressive architecture with 4.4B parameters, it offers under 150ms latency and supports over 80 languages. With unique inline control for emotions, laughter, and whispers, Fish Audio S2 enables developers to create lifelike, multi-speaker conversations for real-time applications, live dubbing, and interactive AI experiences.
2026-03-12
--K

Fish Audio S2 Product Information
Fish Audio S2: The Most Expressive Open-Source Voice AI Ever Made
In the rapidly evolving landscape of artificial intelligence, Fish Audio S2 emerges as a groundbreaking solution for developers and creators seeking the pinnacle of vocal realism. As the most expressive voice AI ever developed, Fish Audio S2 bridges the gap between synthetic speech and human emotion. This open-source powerhouse is designed to handle complex tasks including Text to Speech, Voice Cloning, and Speech to Text with unprecedented nuance and speed.
What's Fish Audio S2?
Fish Audio S2 (specifically the S2 Pro model) is a leading-edge text-to-speech model that provides users with fine-grained, inline control over prosody and emotion. Unlike traditional TTS engines that sound robotic or flat, Fish Audio S2 is built on a sophisticated Dual-Autoregressive (Dual-AR) architecture. This includes a 4B-parameter "Slow AR" for semantic prediction and a 400M-parameter "Fast AR" to handle intricate acoustic details.
Trained on a massive dataset of over 10 million hours of audio across 80+ languages, Fish Audio S2 utilizes reinforcement learning alignment to ensure the highest quality output. Whether you are looking for Voice Cloning capabilities or a robust API for Text to Speech, Fish Audio S2 offers the model weights and inference code necessary to run high-performance audio applications on your own infrastructure.
Key Features of Fish Audio S2
1. Ultra-Low Latency Performance
Speed is critical for interactive applications. Fish Audio S2 boasts a response time of under 150ms. On high-end hardware like the NVIDIA H200 GPU, the model achieves a time-to-first-audio of approximately 100ms. This makes Fish Audio S2 the ideal choice for real-time conversational AI and live dubbing.
2. Open Domain Control & Multi-Speaker Support
Fish Audio S2 allows for seamless multi-speaker conversations within a single generation. Users can switch between different voices naturally, making it perfect for storytelling or complex dialogue.
3. Fine-Grained Inline Emotion Control
One of the standout features of Fish Audio S2 is its ability to interpret natural-language instructions directly within the text. By using [tag] syntax, you can control paralanguage elements such as:
- [giggles] or [laughing]
- [whispering] or [whisper in small voice]
- [clears throat], [inhale], or [sighing]
- [emphasis] and [pause]
- [professional broadcast tone] or [excited]
4. Fully Open-Source
Transparency and flexibility are at the core of Fish Audio S2. Both the inference code and model weights are open-source. This prevents vendor lock-in and allows developers to fine-tune the model on their own specific data sets.
5. Massive Language Support
Fish Audio S2 supports over 80 languages, categorized by quality tiers:
- Tier 1: English, Chinese, and Japanese.
- Tier 2: Spanish, Korean, Portuguese, Russian, Arabic, French, and German.
- Other supported languages: Hindi, Italian, Turkish, Dutch, Thai, Vietnamese, Swedish, and more.
Use Cases for Fish Audio S2
Fish Audio S2 is a versatile tool that caters to various industries and creative projects:
- Conversational Chatbots: Create highly responsive and emotionally intelligent virtual assistants that respond in under 150ms.
- Audiobooks & Story Studio: Use the [tag] system to bring characters to life with distinct emotions, whispers, and sighs.
- Voiceovers for Video: Generate professional-grade narrations with specific tones like [professional broadcast tone].
- Game Development: Implement lifelike character voices that can react dynamically to gameplay events.
- Accessibility: Provide high-quality Text to Speech for individuals with visual impairments or reading difficulties.
- Localization: Use the Speech to Text and translation capabilities to reach a global audience in 80+ languages.
How to Use Fish Audio S2
Developers can easily integrate Fish Audio S2 into their workflows using the provided API. Below is a basic example of how to generate lifelike speech using the Python client.
Implementation Example
from fishaudio import FishAudio
from fishaudio.utils import save
# Initialize with your API key
client = FishAudio(api_key="your_api_key_here")
# Generate speech with the S2 Pro model
audio = client.tts.convert(
text="Fish Audio S2 is the best voice AI model.",
model="s2-pro"
)
# Save the generated audio file
save(audio, "welcome.mp3")
Frequently Asked Questions (FAQ)
What makes Fish Audio S2 different from other TTS models?
Fish Audio S2 is built from the ground up for expressiveness and openness. While many models offer static voices, Fish Audio S2 provides open-ended expression control through more than 15,000 unique tags, allowing for elements like laughter, singing, and sighs to be embedded directly into the text.
What are the hardware requirements for S2 Pro?
While it can be integrated via API, those running it locally will benefit from high-end GPUs. For instance, on an NVIDIA H200, Fish Audio S2 achieves a Real-Time Factor (RTF) of 0.195 and a throughput of over 3,000 acoustic tokens per second.
How does the licensing work?
Fish Audio S2 is licensed under the Fish Audio Research License. It is free for research and non-commercial use. However, commercial use requires a separate license. You should contact the Fish Audio business team for commercial inquiries.
Can I perform Voice Cloning with Fish Audio S2?
Yes, Fish Audio S2 supports advanced Voice Cloning, allowing users to replicate specific vocal characteristics for highly personalized audio generation.
What is SGLang?
Fish Audio S2 utilizes an SGLang-based inference engine. This allows the model to inherit advanced LLM-native optimizations like continuous batching, paged KV cache, and RadixAttention-based prefix caching for superior performance.