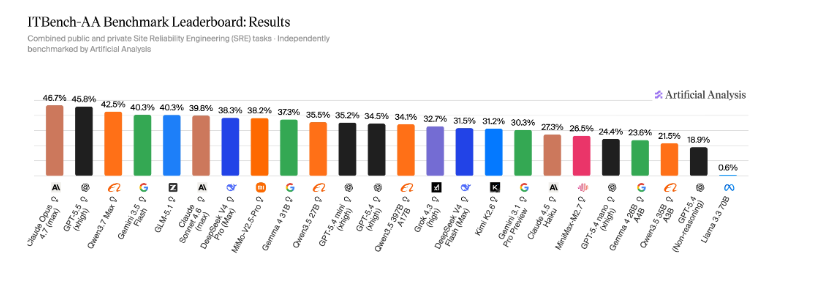
Frontier AI Models Score Below 50% on New ITBench-AA Enterprise IT Benchmark
IBM Research and Artificial Analysis have introduced ITBench-AA, the first benchmark specifically designed to evaluate AI models on agentic enterprise IT tasks. The results indicate a significant performance gap in the industry, as even the most advanced frontier models currently score below 50%. This benchmark highlights the complexities of automating IT operations and the current limitations of AI agents in handling real-world enterprise environments. By establishing a standardized testing framework, IBM and Artificial Analysis aim to provide a clearer picture of how AI performs in specialized, high-stakes IT scenarios compared to general-purpose tasks.
Key Takeaways
- New Industry Standard: ITBench-AA is established as the first benchmark specifically targeting agentic enterprise IT tasks.
- Collaborative Effort: The benchmark was developed through a partnership between Artificial Analysis and IBM.
- Performance Gap: Current frontier AI models are struggling with these specialized tasks, with scores falling below the 50% threshold.
- Focus on Agency: The benchmark evaluates "agentic" capabilities, meaning the AI's ability to act autonomously within an IT environment.
In-Depth Analysis
The Challenge of Agentic Enterprise IT
The release of ITBench-AA marks a pivotal moment in the evaluation of artificial intelligence. While general-purpose benchmarks often show frontier models achieving high scores in logic, coding, and language processing, ITBench-AA reveals a different reality for specialized enterprise applications. The benchmark focuses on "agentic" tasks—scenarios where an AI must not only process information but also take autonomous actions to solve complex IT problems. The fact that frontier models are scoring below 50% suggests that the leap from general reasoning to functional enterprise agency remains a significant hurdle for the current generation of AI.
A Collaborative Benchmark by IBM and Artificial Analysis
By combining the enterprise expertise of IBM with the analytical rigor of Artificial Analysis, ITBench-AA provides a specialized lens through which to view model performance. Enterprise IT environments are characterized by high stakes, complex legacy systems, and the need for precision. This benchmark is designed to simulate these environments, testing whether frontier models can handle the nuances of IT operations. The results published on the Hugging Face Blog indicate that while these models are powerful, their application in a professional IT capacity requires further refinement and perhaps more specialized training data or architectural improvements.
Industry Impact
The introduction of ITBench-AA is likely to shift the focus of AI development from general performance to specialized utility. For the AI industry, a sub-50% score on a major benchmark serves as a reality check for the readiness of AI agents in the workplace. It provides a roadmap for developers to identify specific weaknesses in autonomous IT troubleshooting, system administration, and network management. Furthermore, this benchmark sets a precedent for other industries to develop their own "agentic" evaluations, moving beyond simple Q&A formats to more complex, action-oriented testing environments. As organizations look to integrate AI into their core infrastructure, ITBench-AA will serve as a critical metric for determining which models are truly enterprise-ready.
Frequently Asked Questions
Question: What is ITBench-AA?
ITBench-AA is the first benchmark designed to evaluate AI models on agentic enterprise IT tasks. It was developed by IBM and Artificial Analysis to test how well AI can perform autonomous actions within a professional IT context.
Question: How did the top AI models perform on this benchmark?
According to the initial results, even the most advanced "frontier" models scored below 50% on the ITBench-AA tasks, indicating that there is still significant room for improvement in AI's ability to handle complex IT operations.
Question: Why is this benchmark significant for the AI industry?
It is significant because it moves away from general language testing and focuses on specific, actionable tasks required in an enterprise setting. It highlights the current limitations of AI agents and provides a standardized way to measure progress in IT automation.
