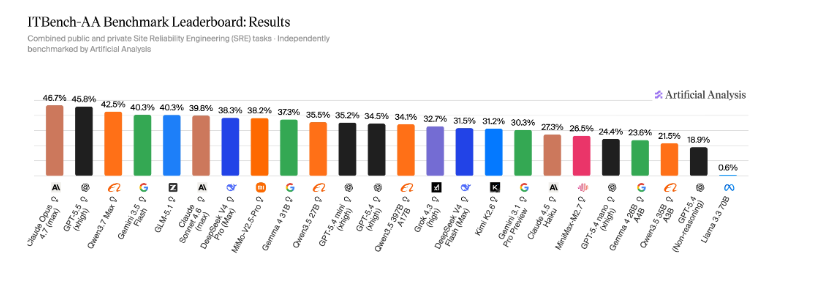
ITBench-AA发布:前沿模型在首个企业级IT智能体基准测试中得分均低于50%
Artificial Analysis与IBM联合发布了首个针对企业级IT任务的智能体基准测试ITBench-AA。测试结果显示,目前最先进的前沿AI模型在处理复杂的企业IT任务时表现欠佳,得分均未超过50%。这一结果揭示了当前AI模型在自动化企业IT运维和执行代理任务方面仍面临巨大挑战,距离完全胜任企业级需求仍有较大差距。
核心要点
- 联合发布:Artificial Analysis与IBM合作推出了ITBench-AA,这是首个专注于企业级IT任务的智能体(Agentic)基准测试。
- 表现欠佳:测试结果显示,目前所有的前沿AI模型在该基准测试中的得分均低于50%。
- 评估维度:该基准测试旨在评估AI模型作为智能体处理复杂、多步骤的企业IT运维任务的能力。
详细分析
ITBench-AA基准测试的背景
Artificial Analysis与IBM联合推出了名为ITBench-AA的新型基准测试。这是业界首个专门针对企业级IT环境中的智能体任务设计的评估工具。随着企业对AI自动化需求的增加,如何衡量AI在实际业务流程和IT运维中的表现变得至关重要,ITBench-AA的出现填补了这一领域的空白。
前沿模型的表现瓶颈
根据发布的数据,即便是目前最强大的前沿AI模型,在ITBench-AA测试中的得分也未能突破50%的大关。这表明,尽管AI在通用对话和基础代码编写方面取得了显著进步,但在处理具有高度复杂性、严谨逻辑要求和企业级环境约束的IT任务时,目前的模型仍存在明显的局限性。这些任务通常需要模型具备极高的推理能力和对IT系统深度的理解。
行业影响
ITBench-AA的发布为企业级AI应用设立了新的性能标杆。得分普遍偏低的现状提醒行业,将AI模型转化为能够独立处理IT任务的“智能体”仍需大量的研发投入。这可能会促使模型开发者从追求通用能力转向更加关注模型在特定垂直领域(如IT运维、系统管理)的推理和执行能力。对于企业而言,在部署AI智能体处理核心IT业务时,仍需保持审慎态度。
常见问题
什么是ITBench-AA?
ITBench-AA是由Artificial Analysis和IBM联合开发的基准测试,专门用于评估AI模型在执行企业级IT智能体任务时的实际表现。
为什么前沿模型的得分会低于50%?
这反映了企业级IT任务的复杂性。这类任务通常涉及多步骤的逻辑推理、对特定IT环境的适应以及极高的准确性要求,目前的通用前沿模型在处理这些专业且复杂的代理任务时,其可靠性和执行能力尚不足以达到高分水平。


