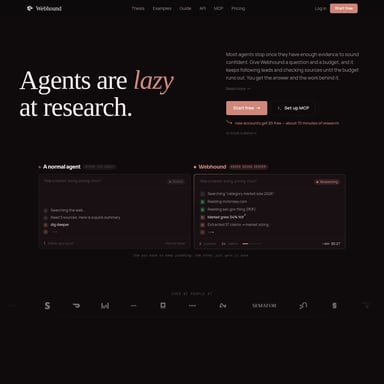
Firecrawl Research Index
Firecrawl Research Index: The Comprehensive Search Index for Scientific and Engineering Research Agents
Firecrawl Research Index is a specialized toolset designed for scientific and engineering research agents. It enables users to search for papers, inspect canonical metadata, read full-text passages, and explore related works through semantic expansion. Additionally, it provides a unique search capability over GitHub history, including issues, pull requests, and READMEs, allowing for a deep dive into implementation notes and engineering prior art.
2026-06-20
212.9K

Firecrawl Research Index Product Information
Firecrawl Research Index: The Ultimate Tool for Scientific and Engineering Discovery
In the rapidly evolving landscape of artificial intelligence and technical documentation, the Firecrawl Research Index stands out as a purpose-built solution designed specifically for scientific and engineering research agents. This advanced index provides a dedicated research-specific toolset, enabling developers and researchers to navigate the complexities of academic papers and engineering repositories with unprecedented precision. By leveraging the Firecrawl Research Index, users can move beyond simple keyword searches to discover deep implementation details, structural paper relations, and canonical metadata.
What is Firecrawl Research Index?
The Firecrawl Research Index is a specialized search and retrieval system that allows agents to find papers by topic, method, benchmark, author, or category. Unlike generic search engines, the Firecrawl Research Index is optimized for the discovery of technical knowledge, exposing high-level metadata alongside specific full-text passages. Whether you are building an AI platform that requires grounded research or an engineering agent looking for specific implementation notes, this index provides the structured data necessary for high-quality technical outcomes.
At its core, the Firecrawl Research Index serves as a bridge between raw scientific publications and actionable insights. It allows for the exploration of canonical paper metadata, source IDs, and the expansion from seed papers to broader research neighborhoods, including citers and references. This makes the Firecrawl Research Index an essential component for any project requiring deep research capabilities.
Key Features of Firecrawl Research Index
The Firecrawl Research Index is packed with features designed to streamline the research process for both human users and AI agents. Below are the primary functionalities that make this index a leader in technical data retrieval:
Comprehensive Paper Search
Users can find papers based on a wide variety of criteria, including specific methods, authors, or research categories. The Firecrawl Research Index returns ranked results that include:
- PaperId: The canonical identifier for the paper.
- PrimaryId: The preferred source-specific ID.
- Metadata: Titles, abstracts, and ranking signals.
- Source IDs: Traceable IDs back to the original publication source.
Full-Text Passage Retrieval
One of the most powerful features of the Firecrawl Research Index is the ability to read specific passages within a paper. This is particularly useful for verifying whether a candidate paper contains a specific method, dataset, constraint, or result before committing to a full read or inclusion in a dataset. This targeted extraction ensures that agents only process the most relevant information.
Structural Research Expansion
Building a bibliography is made easy through semantic expansion. The Firecrawl Research Index allows users to expand from a "seed paper" to find related work through various modes:
- Similar: Finds papers in the co-citation and bibliographic-coupling neighborhood.
- Citers: Identifies papers that have cited the seed paper.
- References: Retrieves the papers that were cited by the seed paper.
GitHub Engineering Integration
Beyond academic papers, the Firecrawl Research Index offers a unique ability to search through GitHub history. This includes searching through repository READMEs, issues, pull requests, and discussions. This feature is invaluable for finding implementation notes, bug reports, and design discussions that are often missing from formal academic publications.
How to Use Firecrawl Research Index
Integrating the Firecrawl Research Index into your workflow is straightforward, whether you are using the CLI, API, or an MCP server. For the best experience with AI agents, it is strongly recommended to use the dedicated research skill.
Installation and Setup
To give your agent immediate access to the Firecrawl Research Index, you can install the research skill using the following command:
npx skills add firecrawl/skills@firecrawl-research-index
Core Endpoints
The Firecrawl Research Index exposes several key endpoints for data retrieval. All endpoints are accessible via the base URL https://api.firecrawl.dev/v2/.
| Task | Endpoint |
| :--- | :--- |
| Search papers | GET /search/research/papers |
| Inspect metadata/passages | GET /search/research/papers/{id} |
| Find related papers | GET /search/research/papers/{id}/similar |
| Search GitHub history | GET /search/research/github |
Searching for Papers via API
You can query the Firecrawl Research Index using natural language. For example, to search for papers on "diffusion image synthesis," you can use a cURL command:
curl -s "https://api.firecrawl.dev/v2/search/research/papers?query=diffusion%20image%20synthesis&k=20"
Optional filters include:
- authors: Filter by author substrings.
- categories: Filter by specific paper categories (e.g.,
cs.LG). - from/to: Set inclusive date bounds using the
YYYY-MM-DDformat.
Expanding Research with Intent
To find papers related to a specific intent, such as "efficient transformers," you can use the similarity endpoint:
curl -s "https://api.firecrawl.dev/v2/search/research/papers/arxiv:1706.03762/similar?intent=efficient%20transformers&mode=similar&k=20"
Use Cases for Firecrawl Research Index
The versatility of the Firecrawl Research Index makes it suitable for a wide range of industries and technical applications:
- AI Platforms: Use the index to ground AI responses in peer-reviewed scientific literature and verified engineering notes.
- Deep Research: Accelerate the literature review process by programmatically expanding from seed papers to entire research neighborhoods.
- Lead Enrichment: Identify authors and contributors in specific niche technical fields for networking or recruitment.
- SEO Platforms: Analyze technical trends and benchmarks to create authoritative content based on the latest scientific advancements.
- Engineering Troubleshooting: Search GitHub history via the Firecrawl Research Index to find implementation notes and bug discussions for specific technical frameworks.
FAQ
Q: Do I need an API key to use Firecrawl Research Index?
A: You can get started without an API key for initial exploration. However, to benefit from higher rate limits, you should add your key to the header: -H "Authorization: Bearer $FIRECRAWL_API_KEY".
Q: What identifiers can I use to inspect a paper?
A: You can use a canonical paperId or a source-specific primaryId (such as an ArXiv ID like arxiv:1706.03762) to inspect metadata or read passages within the Firecrawl Research Index.
Q: How does the GitHub search work? A: The GitHub history search within the Firecrawl Research Index queries repository READMEs, issues, PRs, and discussions. The results include the repository URL, metadata, snippets, and matched markdown content when available.
Q: Can I filter paper searches by date?
A: Yes, the Firecrawl Research Index supports from and to filters using the YYYY-MM-DD format to narrow down results by their creation or update timestamps.
Q: Where can I find the full documentation index? A: You can fetch the complete documentation index at /llms.txt to discover all available pages before exploring further.
Ready to build? Start getting web data for free and scale seamlessly as your project expands with the Firecrawl Research Index. No credit card is needed to get started.