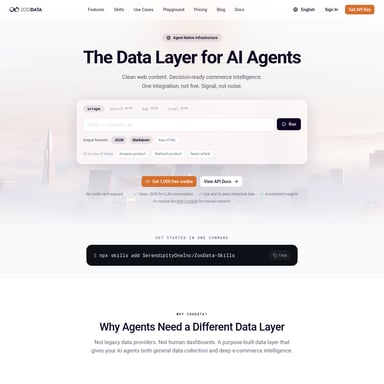
Respan Gateway
Respan Gateway: De Ultieme AI Gateway voor Productie-Grade LLM-Routing en Modelbeheer
Ontdek Respan Gateway, een krachtige AI Gateway voor het routeren van meer dan 500 LLM-modellen. Maximaliseer uptime met automatische failover, verlaag kosten via geavanceerde caching en behoud volledige controle met uitgebreide logging en spend limits. Respan biedt een veilige, schaalbare oplossing voor AI-teams, ondersteund door ISO 27001, SOC 2 en GDPR-certificeringen.
2026-06-13
--K

Respan Gateway Productinformatie
Respan Gateway: De Geavanceerde AI Gateway voor Optimale LLM-Routing
In de huidige wereld van kunstmatige intelligentie is het beheren van verschillende Large Language Models (LLM's) een complexe en tijdrovende taak geworden voor ontwikkeltuams. Respan Gateway biedt de oplossing als een robuuste AI Gateway die speciaal is ontworpen voor productieomgevingen. Met Respan Gateway krijgt u toegang tot een verenigde router of een provider-passthrough voor meer dan 500 verschillende modellen, compleet met functies zoals automatische failover, response caching, en gedetailleerde metadata bij elke aanvraag.
Wat is Respan Gateway?
De Respan Gateway is een centraal controlepunt voor al uw AI-modelinteracties. Het fungeert als een intelligente tussenlaag tussen uw applicatie en honderden LLM-providers. Of u nu gebruikmaakt van OpenAI, Anthropic, Gemini of open-source modellen via Fireworks of Groq, de Respan Gateway stroomlijnt deze verbindingen via één enkele API.
Het platform stelt teams in staat om OpenAI-stijl calls te routeren naar een breed scala aan modellen. U kunt kiezen voor een verenigde router die de beste paden selecteert, of een directe passthrough behouden voor de native SDK van een specifieke provider. Het belangrijkste voordeel is dat elke interactie centraal wordt gelogd, gemonitord en beheerd, wat essentieel is voor schaalbare AI-oplossingen in productie.
Belangrijkste Kenmerken van de Respan Gateway
Respan Gateway is uitgerust met een breed scala aan functies die direct de grootste pijnpunten van AI-engineering aanpakken:
1. Eén API voor Elk Model
Met de Respan Gateway hoeft u niet langer tientallen verschillende SDK's en API-sleutels te beheren. Routeer uw calls naar meer dan 500 modellen met een consistente interface. Dit vereenvoudigt de codebasis en versnelt de ontwikkeling aanzienlijk.
2. Automatische Failover en Betrouwbaarheid
Modellen kunnen falen of tegen rate-limits aanlopen. Respan Gateway voorkomt downtime door automatisch over te schakelen naar het volgende model in uw fallback-lijst. U kunt de load balanceren over verschillende keys en retries met backoff configureren vanaf één centrale plek.
3. Spend Limits en Kostenbeheersing
Voorkom onverwachte kosten door soft warnings of harde limieten (hard caps) in te stellen per API-sleutel. Ontvang direct meldingen via Slack of e-mail wanneer een drempelwaarde wordt overschreden. Dit geeft teams de vrijheid om te experimenteren zonder het budget uit het oog te verliezen.
4. Geavanceerde Response Caching
Verlaag zowel de latentie als de kosten door herhaalde prompts te cachen. Respan Gateway stelt u in staat om antwoorden te hergebruiken, waarbij u specifieke cache-instellingen kunt configureren, zoals cache_by_customer, om ervoor te zorgen dat data veilig en gescheiden blijft tussen verschillende gebruikers.
5. Uitgebreide Tracing en Logging
Elke call via de gateway wordt omgezet in een trace-tree. Hierdoor krijgt u inzicht in de latentie van elke span. Door customer_identifier en extra metadata toe te voegen, kunt u logs en traces eenvoudig filteren op basis van feature, klant of specifieke threads.
Hoe Gebruikt u de Respan Gateway?
Het implementeren van de Respan Gateway in uw bestaande stack is eenvoudig en vereist minimale codewijzigingen. Volg deze stappen om aan de slag te gaan:
- Verkrijg uw Respan API-key: Meld u aan op het platform en maak uw eerste sleutel aan op de API-sleutelpagina.
- Voeg Provider Credentials toe: Verbind uw favoriete providers (zoals OpenAI of Anthropic) via de Integraties-sectie of voeg credits toe aan uw Billing.
- Kies Router of Passthrough: Gebruik de OpenAI-stijl basis-URL (
https://api.respan.ai/api/) of gebruik de native URL's voor Anthropic en Gemini. - Stuur Parameters mee: Optimaliseer uw calls door metadata, fallback-modellen en cache-instellingen mee te sturen in de
extra_body.
Voorbeeld in Python
Hieronder ziet u hoe eenvoudig het is om de Respan Gateway te integreren met de standaard OpenAI Python-bibliotheek:
from openai import OpenAI
client = OpenAI(
base_url="https://api.respan.ai/api/",
api_key="YOUR_RESPAN_API_KEY",
)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "Hello!"}],
extra_body={
"customer_identifier": "user_123",
"metadata": {"feature": "chatbot", "environment": "production"},
"fallback_models": ["claude-sonnet-4-20250514", "gemini-2.5-flash"],
"cache_enabled": True,
"cache_ttl": 600,
"cache_options": {"cache_by_customer": True},
},
)
print(response.choices[0].message.content)
Gebruiksscenario's voor AI Gateway Optimalisatie
De Respan Gateway is essentieel in verschillende scenario's waar betrouwbaarheid en schaalbaarheid cruciaal zijn:
- AI-Agenten in Productie: Wanneer uw applicatie afhankelijk is van AI-agenten die autonoom taken uitvoeren, zorgt de gateway ervoor dat zij altijd online blijven via fallback-mechanismen.
- Kostenbeheersing voor SaaS: SaaS-bedrijven die LLM-functies aanbieden aan hun klanten, kunnen per klant limieten instellen en het verbruik nauwkeurig traceren met de
customer_identifier. - Latency-gevoelige Applicaties: Door gebruik te maken van caching kunnen veelvoorkomende vragen direct worden beantwoord met een latentie van 0ms, wat de gebruikerservaring drastisch verbetert.
- Multi-Model Strategieën: Teams die niet afhankelijk willen zijn van één provider (vendor lock-in), kunnen moeiteloos wisselen tussen verschillende modellen om de beste prijs-kwaliteitverhouding te vinden.
Veiligheid en Compliancy
Respan zet zich in voor de hoogste normen op het gebied van informatiebeveiliging. De Respan Gateway voldoet aan de volgende internationale standaarden:
- ISO 27001: De internationaal erkende standaard voor informatiebeveiligingsbeheer.
- SOC 2: Waarborgt een veilig en compliant beheer van gegevens over alle systemen.
- GDPR: Volledige naleving van de striktste privacynormen ter wereld voor wereldwijde operaties.
- HIPAA: Compliant met HIPAA-richtlijnen voor organisaties in de gezondheidszorg, inclusief de beschikbaarheid van een Business Associate Agreement (BAA).
Veelgestelde Vragen (FAQ)
V: Wat gebeurt er als een model een rate-limit bereikt?
A: Indien geconfigureerd, zal de Respan Gateway automatisch het volgende model in uw fallback_models lijst proberen. Dit minimaliseert de impact op de eindgebruiker.
V: Hoe voorkom ik dat cache-antwoorden tussen klanten worden gedeeld?
A: Door de optie cache_by_customer in te schakelen, zorgt de gateway ervoor dat gecachte antwoorden alleen beschikbaar zijn voor de specifieke klant-ID die de oorspronkelijke aanvraag deed.
V: Kan ik de logging uitschakelen om de privacy te verhogen?
A: Ja, met de functies disable_log en omit_log kunt u instellen dat alleen metrieken worden opgeslagen zonder de volledige request/response payloads vast te leggen.
V: Ondersteunt Respan Gateway ook streaming? A: Ja, Respan is gebouwd voor AI-agenten en ondersteunt streaming edge cases, waarbij u parameters zoals retries en cache-policy nauwkeurig kunt afstemmen.
V: Welke providers worden ondersteund? A: De gateway werkt met alle grote providers, waaronder OpenAI, Anthropic, Google Gemini (via Vertex AI en Google AI), AWS Bedrock, Azure OpenAI, en gespecialiseerde providers zoals Groq en Perplexity.
Met de Respan Gateway kiest u voor een toekomstbestendige infrastructuur die uw AI-workflows sneller, goedkoper en betrouwbaarder maakt. Begin vandaag nog gratis en ervaar de kracht van een verenigde AI Gateway.