GenericAgent: Self-Evolving AI Agent Achieves Full System Control with 6x Lower Token Consumption
GenericAgent, a new self-evolving intelligent agent developed by lsdefine, has emerged as a highly efficient solution for system control. Starting from a compact foundation of just 3.3K lines of seed code, the agent is capable of growing its own skill tree autonomously. One of its most significant breakthroughs is its operational efficiency; it achieves complete system control while consuming six times fewer tokens compared to traditional methods. This development represents a shift toward more resource-efficient and autonomous AI architectures, focusing on self-evolution and minimized computational overhead. By leveraging a streamlined codebase to build complex capabilities, GenericAgent demonstrates a scalable approach to AI-driven system management and task execution.
Key Takeaways
- Self-Evolving Architecture: GenericAgent grows its own skill tree starting from a minimal base of 3.3K lines of seed code.
- High Efficiency: The system achieves full control while utilizing 6x fewer tokens than standard implementations.
- Compact Foundation: The entire framework is built upon a highly optimized and small codebase.
- Comprehensive Control: Despite its efficiency, it maintains the ability to perform complete system-level operations.
In-Depth Analysis
The Evolution of the Skill Tree
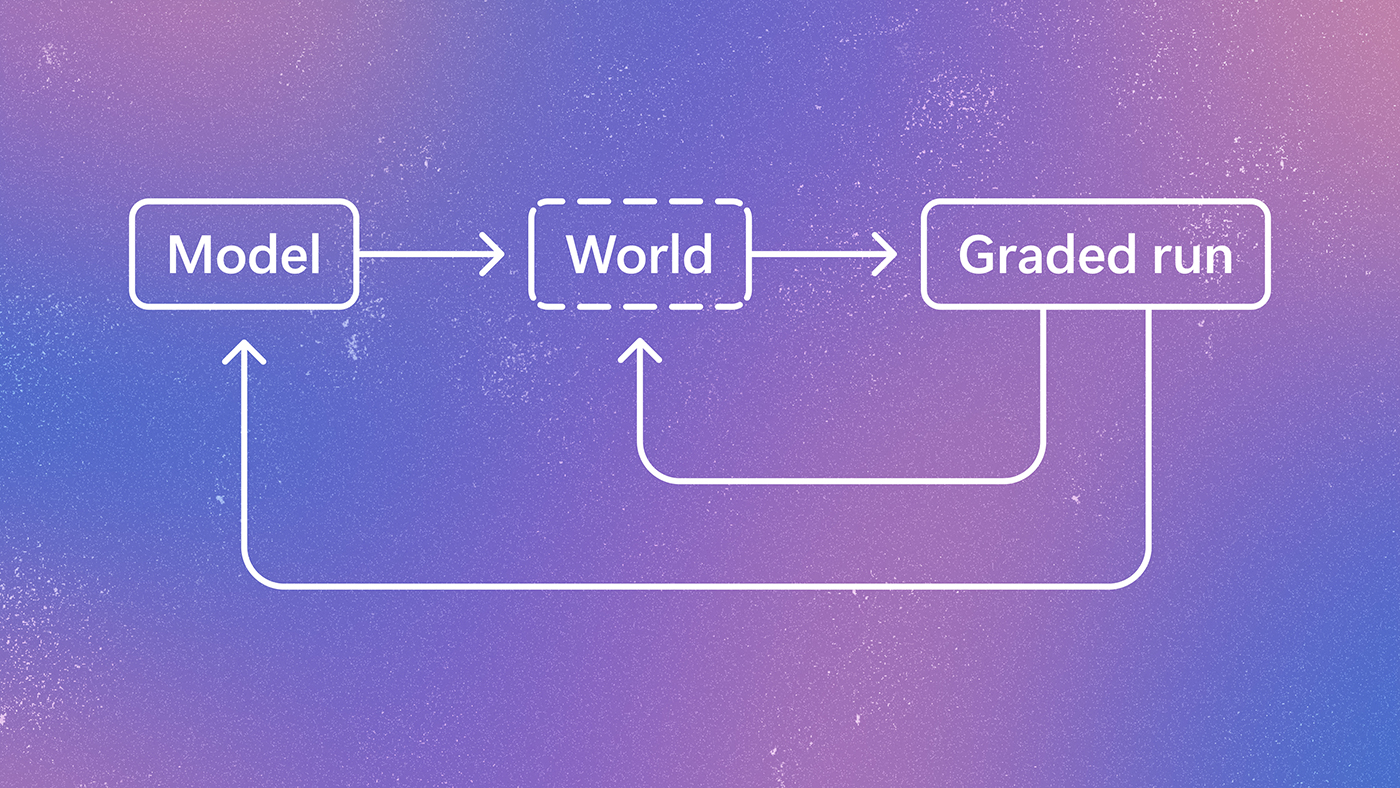
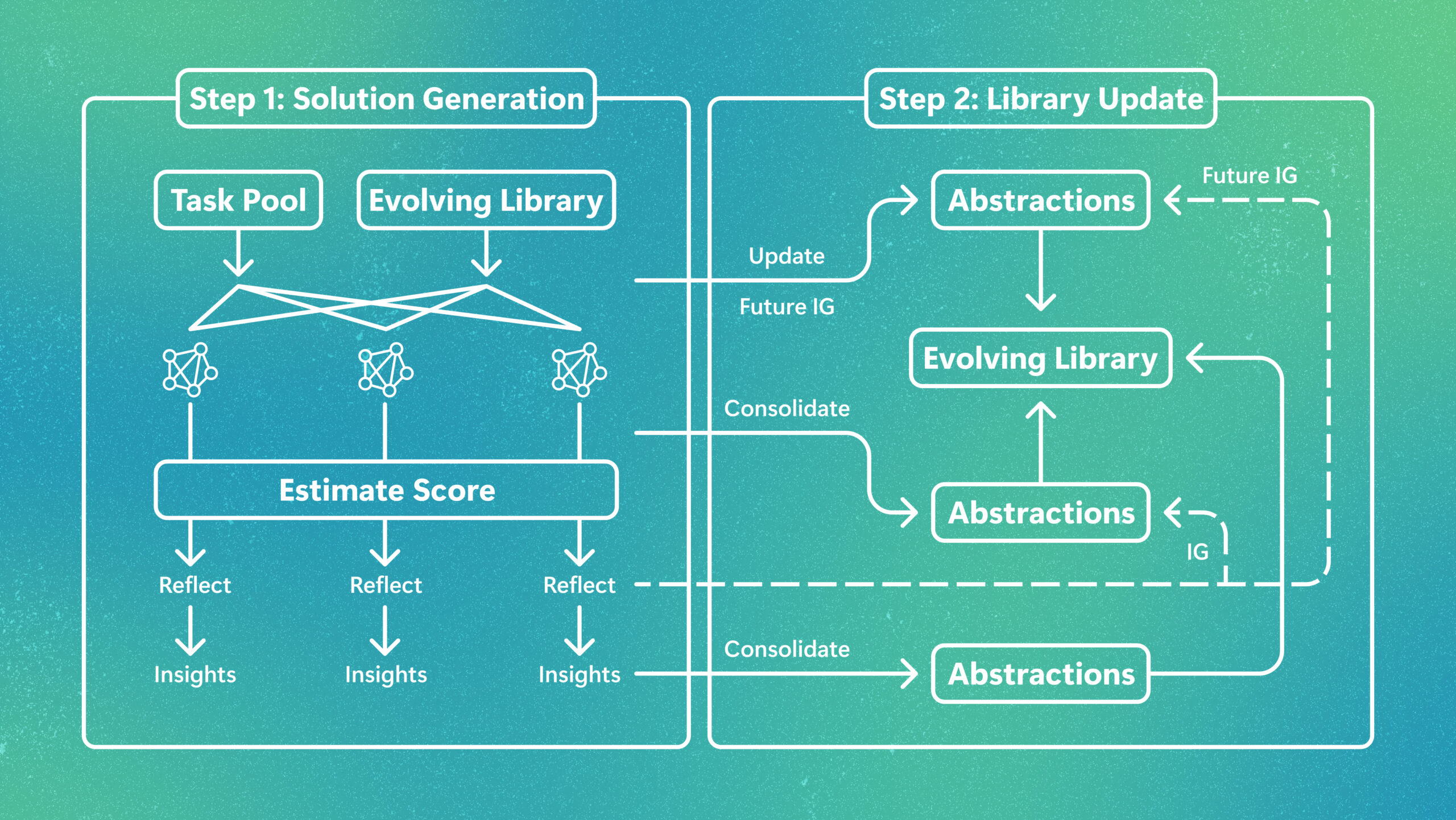
GenericAgent introduces a unique approach to AI development by utilizing a "self-evolution" mechanism. Rather than being pre-programmed with every possible function, the agent starts with a foundational set of 3.3K lines of seed code. From this core, it possesses the capability to grow a complex skill tree. This organic growth allows the agent to adapt and expand its functional repertoire based on the requirements of the system it is controlling, ensuring that the code remains relevant and purpose-driven.
Token Optimization and System Control
Efficiency is a primary pillar of the GenericAgent project. In the current landscape of Large Language Models (LLMs), token consumption often translates directly to cost and latency. GenericAgent addresses this by implementing a strategy that requires 6x fewer tokens to achieve the same level of system control as its predecessors. This reduction in token usage does not compromise its authority over the system; the agent is designed to handle full system control tasks, making it a powerful tool for automated management and complex technical operations.
Industry Impact
The introduction of GenericAgent signals a move toward more sustainable and autonomous AI systems. By proving that a massive codebase isn't necessary to achieve complex system control, it sets a precedent for "lean" AI development. The 6x reduction in token consumption is particularly significant for enterprises looking to scale AI agents without incurring exponential costs. Furthermore, the self-evolving nature of the skill tree suggests a future where AI agents can customize themselves to specific environments with minimal human intervention, potentially lowering the barrier for deploying sophisticated autonomous controllers in various technical sectors.
Frequently Asked Questions
Question: How does GenericAgent manage to use 6x fewer tokens?
GenericAgent is optimized to achieve full system control with significantly lower overhead, resulting in a 6x reduction in token consumption compared to traditional agent frameworks.
Question: What is the significance of the 3.3K lines of seed code?
The 3.3K lines of seed code serve as the starting point for the agent. From this compact foundation, the agent is capable of autonomously growing its own skill tree to handle complex tasks.
Question: Who is the developer of GenericAgent?
GenericAgent was developed by the creator known as lsdefine and has been featured as a trending project on GitHub.