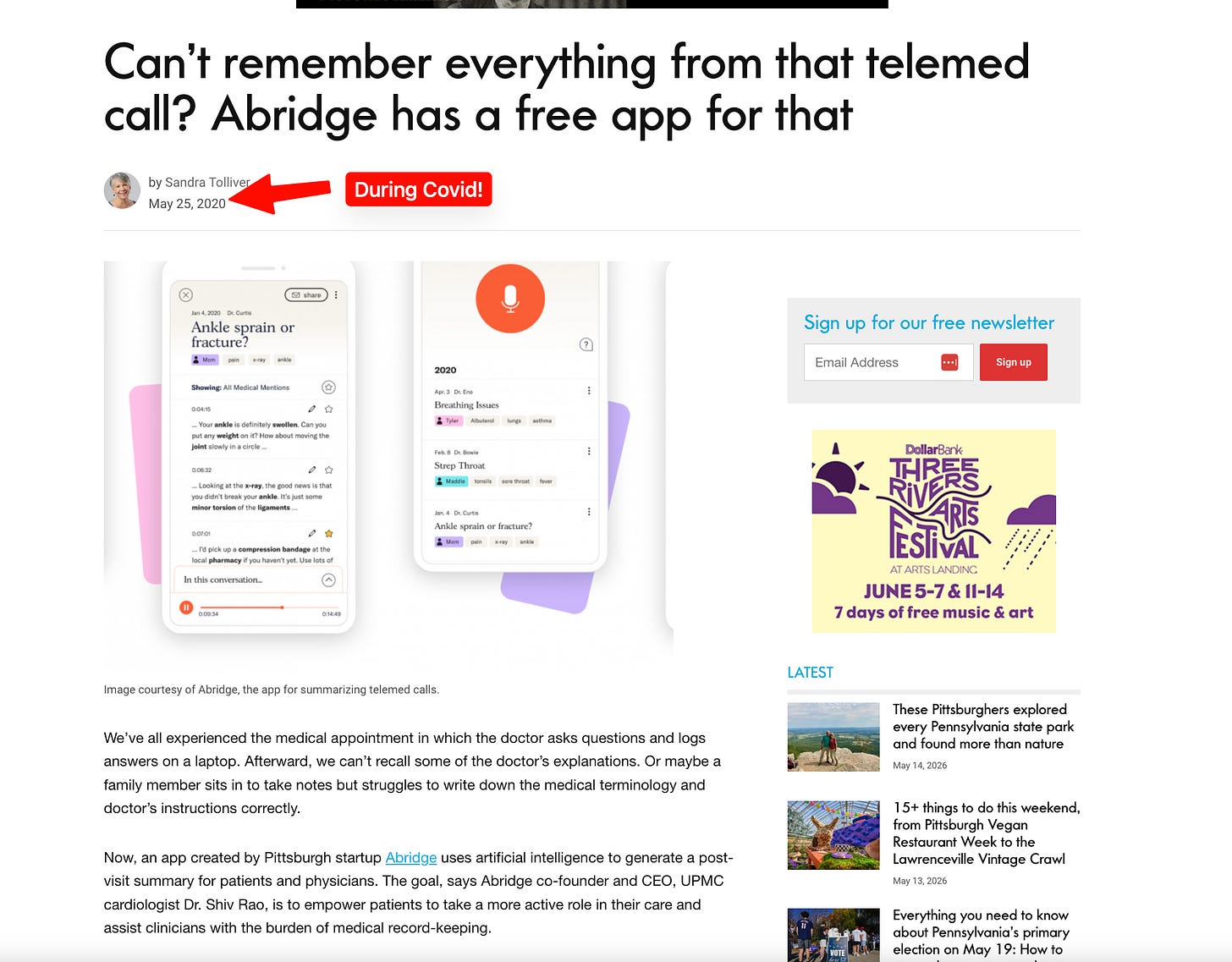
AI-Native Healthcare: How Abridge is Transforming 100 Million Doctor Visits and Saving Clinicians 20 Hours Weekly
Abridge is revolutionizing the medical field by positioning the patient-clinician conversation as the central 'operating system' of healthcare. Led by insights from Janie Lee and Chai Asawa, the platform is scaling to manage 100 million doctor visits, significantly reducing the administrative burden on medical professionals. By leveraging AI-native technology, Abridge enables clinicians to save between 10 and 20 hours of work, while streamlining critical processes such as prior authorization—turning a task that previously took much longer into one completed in mere minutes. This shift marks a significant move toward integrated, conversational AI in clinical environments.
Key Takeaways
- Massive Scale: Abridge is targeting the management of 100 million doctor visits through its AI-native platform.
- Significant Time Recovery: Clinicians using the system can save between 10 to 20 hours of administrative work per week.
- Rapid Prior Authorization: The technology reduces the time required for prior authorization from traditional durations to just minutes.
- Conversational Operating System: The platform aims to turn the natural dialogue between patients and clinicians into the foundational data layer for healthcare operations.
In-Depth Analysis
The Evolution of the Healthcare Operating System
As discussed by Janie Lee and Chai Asawa, Abridge is moving beyond simple documentation tools to create what is described as an "operating system" for healthcare. By capturing and analyzing the conversation between clinicians and patients, the platform transforms raw dialogue into structured, actionable data. This approach allows the conversation itself to drive the administrative and clinical workflows that were previously manual and fragmented.
Quantifying Clinician Efficiency and Workflow Impact
The impact of Abridge is measured primarily through time reclaimed by medical professionals. With clinicians saving 10 to 20 hours, the platform addresses the primary cause of professional burnout: administrative overhead. Furthermore, the efficiency gains extend to complex bureaucratic tasks. Prior authorization, a notorious bottleneck in patient care, is accelerated to take only minutes, ensuring that treatment plans can proceed without the typical administrative delays.
Industry Impact
Abridge’s model represents a shift toward AI-native healthcare where the technology is not an add-on but the core infrastructure. By successfully processing 100 million visits, Abridge demonstrates that conversational AI can handle the scale and complexity of the modern medical system. This sets a new industry standard for how clinical documentation and insurance approvals are handled, potentially forcing a broader digital transformation across hospital systems and insurance providers to keep pace with AI-driven speeds.
Frequently Asked Questions
Question: How much time can clinicians expect to save using Abridge?
Answer: Based on the data provided, clinicians can save between 10 and 20 hours of administrative time by utilizing Abridge’s AI-native healthcare tools.
Question: What specific administrative process has seen the most drastic speed improvement?
Answer: Prior authorization has seen a significant improvement, with the process now being completed in minutes rather than the much longer timeframes typically required in traditional healthcare settings.
Question: What is the core philosophy behind Abridge’s technology?
Answer: Abridge operates on the philosophy of turning the patient and clinician conversation into the "operating system" of healthcare, making the dialogue the central source of truth for all subsequent medical and administrative actions.


