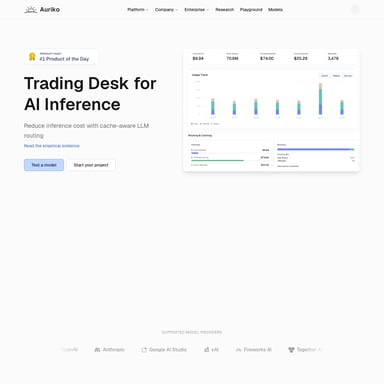
Sifflet Data Observability
数据可观察性:让数据更可靠
数据可观察性是一种监控数据管道的实践,确保数据流动健康,帮助企业确保数据的可靠性,避免决策误差。通过结合技术信号和业务影响,数据可观察性为数据团队提供了前所未有的控制和信任。
2025-07-24
12.6K

Sifflet Data Observability 产品信息
数据可观察性:让数据更可靠
什么是数据可观察性?
数据可观察性是监控和确保数据健康的实践,以确保数据驱动的决策和产品如推荐引擎或AI模型可靠。可以将其视为现代数据堆栈的质量控制。
数据可观察性的目标
随着企业越来越依赖数据,数据问题的代价也在不断增加。数据可观察性帮助及早发现问题,理解其根本原因,并在问题对数据产生信任损害之前解决它。
数据可观察性的核心要素
为了有效地观察数据,首先需要了解数据的基本特征,包括:
1. 指标
数据的内部DNA,描述数据健康的定量特征,如分布、值模式和质量评分。
2. 元数据
使数据具有意义的上下文信息,例如表格描述、列定义、数据类型等。
3. 数据血统
展示数据如何流动及其依赖关系的地图。
4. 日志
捕获所有与数据的交互,包括管道运行、转化、查询等。
数据可观察性的框架
数据可观察性的框架不仅注重技术健康,还要注重其对业务的影响。它依赖五个技术支柱和三个战略支柱:
技术支柱
- 新鲜度:数据是否及时更新?
- 体积:数据量是否符合预期?
- 模式:数据结构是否发生变化?
- 分布:数据值是否在预期范围内?
- 血统:数据如何流动?
战略支柱
- 精准检测:优先级警报根据下游业务使用情况排序。
- 上游与下游的协同工作:确保问题得到快速解决。
数据可观察性与其他工具的区别
与数据监控、数据质量管理或数据治理不同,数据可观察性不仅仅是监控数据流,它能提供具体的业务背景,确保企业能依赖数据做出准确决策。
谁需要数据可观察性?
任何依赖可信数据的团队都需要数据可观察性。从数据工程师到高层管理人员,数据可观察性已成为企业基础设施的一部分,确保数据系统顺畅运行,防止潜在的损失。
如何实施数据可观察性
成功实施数据可观察性需要技术设置和组织协调。首先要从对业务至关重要的数据流程开始,逐步扩展观察范围。
阶段 1:基础设置
在最初的4周内,设置自动化监控,关注五大核心支柱:新鲜度、体积、模式、分布、血统。
阶段 2:情境智能
在接下来的4周内,通过影响评分、根本原因分析工具和跨职能工作流来确保业务上下游之间的有效协作。
阶段 3:加速解决
在最后4周,通过集成通知、自动化操作手册等方式提高问题解决速度。
选择合适的可观察性平台
理想的可观察性平台不仅能检测和警报,还要能提供与业务相关的上下文,帮助团队在正确的时间做出响应。
实施中的常见错误
- 过早产生告警疲劳:从最关键的数据流开始,不要尝试监控所有内容。
- 只关注技术细节:如果没有考虑业务需求,团队无法有效协作解决问题。
结论
数据是企业的基石,而数据平台越来越复杂。数据可观察性为你提供了确保数据系统健康、减少数据停机并提升决策速度的保障。