LLaVA
LLaVA多模态AI视觉理解平台
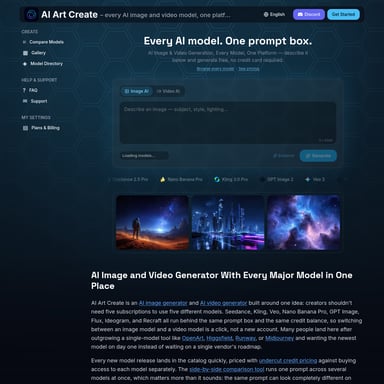
LLaVA是一款由微软与威斯康星大学合作研发的先进多模态AI模型,具备图像与语言双重理解能力。通过LLaVA在线平台,用户可以上传图像并与AI进行自然对话,轻松实现图像内容识别、场景分析、文档处理和智能问答。LLaVA在视觉理解上接近GPT-4水平,支持高分辨率图像处理和多场景应用,适用于教育、医疗、金融、电商、研究等领域。凭借开源生态、端到端训练及92.53%科学问答基准准确率,LLaVA成为智能视觉理解与交互的理想选择。
2025-09-17
--K

LLaVA 产品信息
LLaVA多模态AI平台
什么是LLaVA
LLaVA (Large Language and Vision Assistant) 是微软与威斯康星大学联合研发的突破性多模态人工智能模型。LLaVA AI首次实现端到端训练,结合视觉编码器与语言模型,达到接近GPT-4的视觉理解能力。通过LLaVA在线平台,用户可上传图片并与AI自然对话,实现真正的人机交互式视觉理解。
LLaVA功能特性
视觉理解能力
- LLaVA AI可精准识别图像中的物体、人物、活动和场景关系。
- 适用于复杂图像分析,从医疗影像到教育内容均可处理。
自然语言交互
- 通过LLaVA在线界面进行自然对话,轻松获取图像内容的详细解释。
- 支持多轮对话,保持上下文一致性。
多模态处理
- LLaVA模型将视觉与语言无缝结合,提供类人认知水平的综合理解。
- 实现比单一模态AI更高层次的语境分析。
OCR与推理能力
- 智能识别和提取文档信息,如合同、发票、处方等。
- 提供逻辑性解释,适合学术、金融与法律领域。
高分辨率支持
- 支持最高1344x336像素图像,保持细节与准确性。
研究级准确性
- LLaVA AI在Science QA基准上取得92.53%准确率。
- GPT-4相对得分85.1%,为行业顶级水平。
如何使用LLaVA
- 上传图像:拖拽或点击上传PNG、JPG、WEBP格式文件(最大10MB)。
- 提出问题:输入自然语言问题,如“这张图里的人在做什么?”。
- 获取回答:LLaVA AI智能解析图像,提供详细答案与推理过程。
- 继续对话:可进行多轮交互,探索图像更多细节与场景。
应用场景
- 教育:老师利用LLaVA AI制作互动课程,学生解析复杂图表。
- 电商:自动生成商品描述,提升产品上架效率。
- 医疗:初步分析影像资料,辅助医生文档化处理。
- 金融与法律:扫描合同、票据,自动提取关键信息。
- 内容创作:自动标签、生成社交媒体文案,助力创意输出。
FAQ 常见问题
Q1: LLaVA与其他AI有何不同?
A: LLaVA AI融合视觉与语言,支持自然对话理解图像,准确率接近GPT-4水平。
Q2: LLaVA模型如何工作?
A: LLaVA结合CLIP视觉编码器与Vicuna语言模型,通过投影矩阵实现多模态理解。
Q3: LLaVA在线是否免费?
A: 是的,用户可直接访问LLaVA平台上传图片并体验核心功能,无需注册。
Q4: 哪些图像最适合LLaVA AI?
A: 教育图表、电商产品图、医疗影像、艺术作品与商业文档均适用。
Q5: LLaVA的准确性如何?
A: LLaVA在线在科学问答基准上达到92.53%准确率,稳定性媲美商业级AI。
Q6: 能否用于商业?
A: 可以,零售、营销、医疗、教育等行业均已应用LLaVA AI,支持灵活的开源许可部署。
立即体验LLaVA
现在就访问LLaVA在线平台,上传一张图片,体验前所未有的多模态AI视觉理解与自然语言交互。