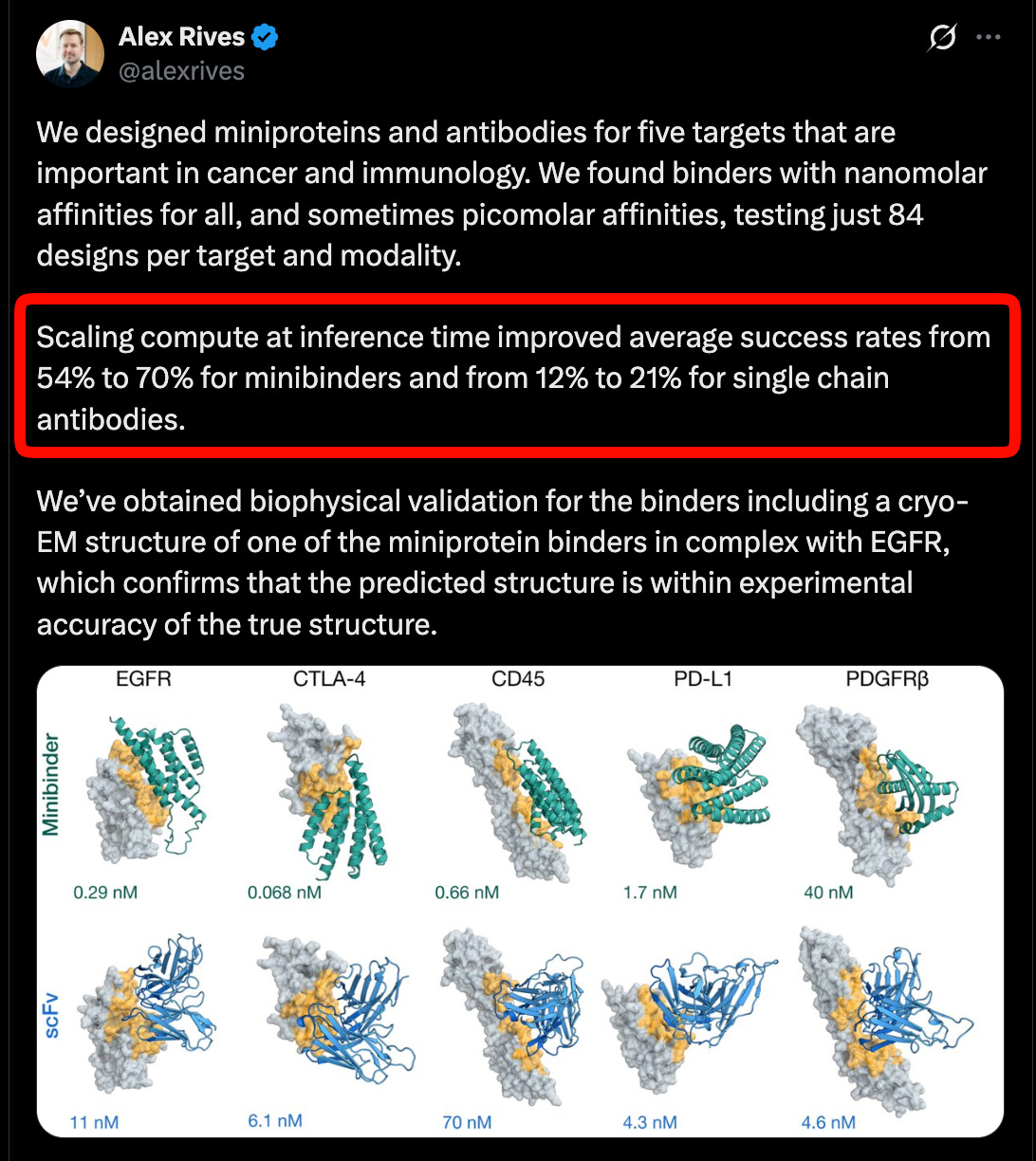
ESMFold2:蛋白质研究的“苦涩教训”,迈向可编程生物学新时代
本文基于 Alex Rives (BioHub) 在 Latent Space 的分享,深入探讨了 ESMFold2 及其对蛋白质科学的影响。核心内容围绕“苦涩的教训”展开,分析了在生物 AI 建模中大规模数据集与归纳偏置的博弈,并阐述了如何通过构建生物世界模型来实现可编程生物学的愿景。
核心要点
- 苦涩的教训(The Bitter Lesson):在蛋白质预测领域,增加计算量和数据规模的通用方法正逐渐超越依赖人类先验知识的特定算法。
- 数据集与归纳偏置:探讨了在模型设计中,过度依赖归纳偏置(Inductive Bias)与利用大规模数据集之间的权衡。
- 生物世界模型:将蛋白质折叠模型视为一种理解生物学底层逻辑的“世界模型”。
- 可编程生物学:通过高精度的 AI 模型,生物学正从发现科学转向可预测、可设计的编程科学。
详细分析
苦涩的教训:数据集与归纳偏置的权衡
在 ESMFold2 的开发逻辑中,Alex Rives 强调了 Rich Sutton 所提出的“苦涩的教训”在生物学领域的体现。传统生物信息学往往依赖于大量的归纳偏置,即通过人工设计的规则和物理约束来指导模型。然而,随着计算能力的提升和蛋白质序列数据库的爆炸式增长,事实证明,能够更好地利用大规模数据的通用学习方法往往能取得突破性的进展。ESMFold2 的演进展示了当模型减少对特定物理结构的硬性假设,转而从海量序列数据中学习模式时,其预测精度和泛化能力得到了显著提升。
生物学作为“世界模型”
新闻中提到的“世界模型”概念,标志着 AI 对生物学的理解已不再局限于简单的结构预测。ESMFold2 不仅仅是一个折叠工具,它更像是一个理解蛋白质语言和生物物理环境的模拟器。通过在海量数据上进行训练,模型捕捉到了蛋白质序列与功能、结构之间的深层关联。这种“世界模型”的视角意味着 AI 能够模拟生物分子在复杂系统中的行为,为理解生命活动的本质提供了新的计算框架。
通往可编程生物学之路
可编程生物学(Programmable Biology)是此次讨论的终极愿景。当模型能够准确预测和模拟蛋白质的行为时,科学家就可以像编写软件代码一样设计新的蛋白质分子。这种转变意味着生物学研究正从“观察与发现”模式转向“设计与构建”模式。通过 ESMFold2 等工具,研究人员可以更精准地操纵生物系统,为合成生物学、药物研发和生物工程开辟了全新的路径。
行业影响
ESMFold2 的相关理念对 AI 行业及生物制药领域具有深远意义。首先,它验证了大规模预训练模型在生命科学领域的有效性,推动了“AI for Science”范式的普及。其次,它加速了蛋白质工程的自动化进程,降低了新药研发的门槛。最重要的是,它提出的“可编程生物学”概念,预示着未来生物技术将与信息技术深度融合,产生巨大的产业协同效应。
常见问题
问题 1:什么是蛋白质研究中的“苦涩教训”?
“苦涩的教训”是指在长期发展中,利用大规模计算和数据的通用方法最终会战胜利用人类专家知识的特化方法。在蛋白质研究中,这意味着大规模预训练模型(如 ESMFold2)在处理复杂生物问题上比传统的人工规则更具优势。
问题 2:为什么“世界模型”对生物学很重要?
世界模型允许 AI 不仅仅是“记住”已知的蛋白质结构,而是理解其背后的生成逻辑。这使得模型能够预测未见过的突变影响,甚至设计出自然界不存在的新型蛋白质。
问题 3:可编程生物学将如何改变药物研发?
它将研发过程从随机筛选转变为定向设计。通过模型预测,科学家可以直接在计算机上设计具有特定功能的蛋白质药物,极大地缩短了实验周期并提高了成功率。


