研究突破人工智能生成式AIWeb技术
生成式视觉互联网新尝试:直接从模型实时流式传输的网站
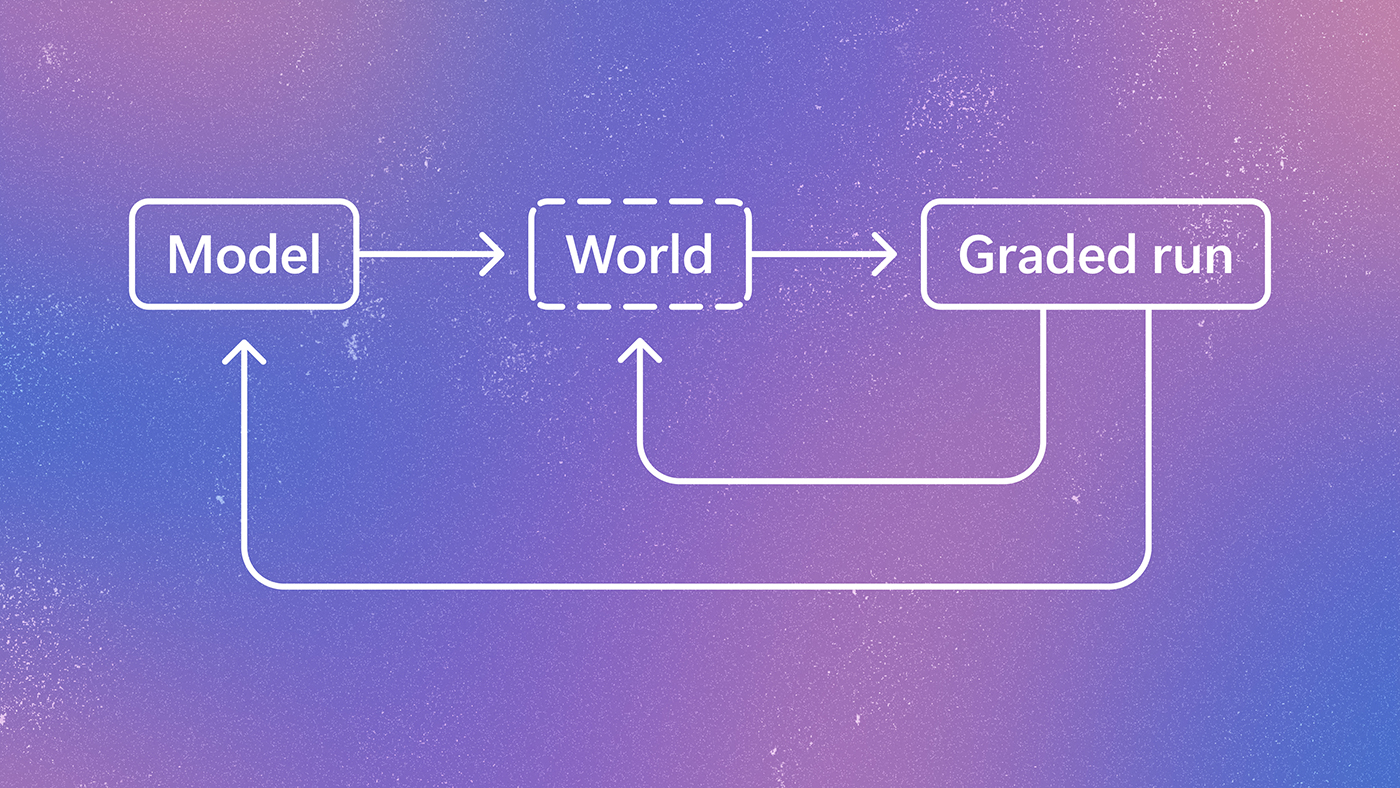
Flipbook.page 提出了一种全新的互联网交互概念——“生成式视觉互联网”。该项目展示了网站内容不再是存储在服务器上的静态文件,而是直接从生成模型中实时流式传输而成的视觉体验。这一突破性尝试挑战了传统网页构建模式,预示着未来互联网内容生成的新范式。
Hacker News
核心要点
- 生成式视觉互联网:提出了一种完全由模型驱动的新型互联网内容呈现方式。
- 实时流式传输:网站内容并非预设,而是直接从模型中实时生成并流式传输给用户。
- 范式转移:从传统的“存储-检索”模式转向“实时生成”模式。
详细分析
实时生成的视觉体验
根据 Flipbook.page 的展示,该项目核心在于“生成式视觉互联网”(Generative Visual Internet)。这意味着用户在浏览器中看到的不再是传统的 HTML、CSS 和 JavaScript 组合,而是由底层生成模型实时计算并输出的视觉流。这种方式打破了静态网页的限制,使得每一次访问都可能产生独特的、动态的视觉反馈。
从模型到浏览器的直接连接
该技术最显著的特点是“直接从模型流式传输”(Streamed live directly from a model)。在传统架构中,内容需要经过后端处理、数据库存储再分发至前端。而在此模式下,模型成为了内容的直接生产者,减少了中间环节,实现了高度的个性化与即时性,为未来沉浸式互联网体验提供了新的技术路径。
行业影响
这一概念的提出对 AI 行业及 Web 开发领域具有重要意义。首先,它重新定义了“网页”的本质,将 AI 模型从辅助工具提升到了基础设施的高度。其次,这种实时生成的模式可能对内容分发网络(CDN)和前端渲染技术产生深远影响。如果该技术得以普及,未来的互联网将变得更加动态和不可预测,极大地丰富了数字内容的表现力。
常见问题
什么是生成式视觉互联网?
生成式视觉互联网是指利用生成式 AI 模型实时创造网页内容和视觉界面的技术,内容不再依赖于预先存储的静态资源,而是根据算法实时生成。
这种方式与传统网站有什么区别?
传统网站是展示存储在服务器上的固定数据,而该项目展示的网站是直接从模型中实时流式传输生成的,具有更强的动态性和生成性特征。