格雷斯·霍珀的复仇:大模型揭示编程语言设计对AI编码效率的影响
本文探讨了AI驱动的代码工作流中存在的语言差异现象。通过分析AutoCodeBench等基准测试数据,文章指出尽管Python和JavaScript拥有庞大的训练数据,但在AI模型中的表现却不如Elixir、Kotlin等语言。这一发现挑战了“数据量决定模型表现”的传统认知,并重新审视了柯尼汉定律在AI时代的意义。
核心要点
- 柯尼汉定律的现代启示:调试难度是编写代码的两倍,过度复杂的代码会导致开发者(及AI)难以维护。
- 基准测试的局限性:当前主流的SWEBench和TerminalBench高度偏向Python,无法全面反映AI在不同语言上的能力。
- 语言表现的逆转:AutoCodeBench数据显示,Elixir、Kotlin和C#在AI模型中的表现优于Python和JavaScript。
- 训练数据并非唯一决定因素:尽管Python拥有海量训练数据,但其在模型中的实际表现却普遍较差。
详细分析
柯尼汉定律与代码复杂性
文章首先引用了著名的柯尼汉定律(Kernighan’s Law):调试代码的难度是编写代码的两倍。这意味着如果开发者在编写代码时用尽了全部聪明才智,那么在调试时他将变得不够聪明。在LLM(大语言模型)时代,这一定律不仅关乎代码逻辑的简洁性,更与编程语言本身的设计密切相关。简单的语言设计不仅有助于人类理解,似乎也更有利于AI模型的推理和生成。
编程语言表现的意外排名
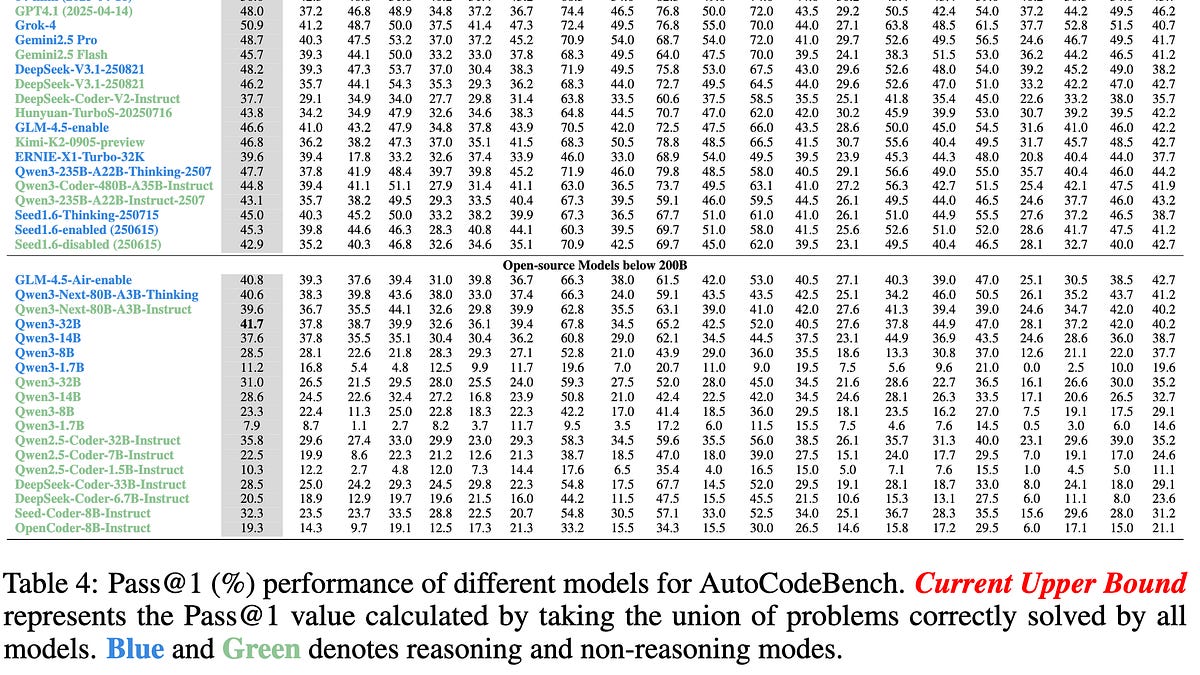
根据AutoCodeBench对20种编程语言的测试结果,AI模型在不同语言上的表现呈现出显著差异。令人意外的是,处于领先地位的是Elixir、Kotlin、Racket和C#;而拥有庞大生态系统和海量训练数据的PHP、JavaScript、Python和Perl则排在末尾。这一结果打破了“训练数据越多,模型表现越好”的固有观念,暗示了语言结构的严谨性或设计模式可能对AI的理解力有更深层的影响。
现有基准测试的偏见
目前衡量软件工程师AI能力的基准测试,如SWEBench,主要集中在Python语言上。TerminalBench虽然涉及更多样化的任务,但在编写代码环节依然倾向于Python。这种对单一语言的依赖掩盖了AI在其他语言环境下的真实潜力,也让那些在特定语言(如Python)中遇到瓶颈的开发者误以为AI编码工具的效果不佳。
行业影响
该发现对AI辅助编程领域具有重要意义。首先,它促使开发者重新评估编程语言的选择,在AI协作时代,语法更严谨、逻辑更清晰的语言(如Kotlin或Elixir)可能会获得更大的生产力优势。其次,这要求基准测试机构开发更具包容性的多语言评估体系,以准确衡量Opus 4.5、Gemini 3等新一代模型的真实水平。最后,这可能引导未来编程语言的设计向“AI友好型”方向演进。
常见问题
问题:为什么Python在AI模型中的表现反而不如Elixir?
根据AutoCodeBench的数据,尽管Python训练数据极多,但其表现却处于末尾。这可能与语言设计的复杂性、动态特性以及代码库中存在的冗余或不一致模式有关,而Elixir等语言可能具有更易于模型捕捉的结构化特征。
问题:什么是AutoCodeBench?
AutoCodeBench是一个不同于SWEBench的基准测试工具,它不仅测试不同的AI模型,还跨越了20种不同的编程语言,旨在提供更全面的AI编码能力评估。
问题:柯尼汉定律在AI时代还有效吗?
依然有效。文章认为,柯尼汉定律关于“保持代码简单以便于推理”的核心思想在AI时代同样适用。如果代码或语言设计过于复杂,即使是先进的AI模型在处理和调试时也会遇到困难。


