HasData
HasData: Servicio de web scraping para pipelines de datos e IA que convierte URLs en JSON o Markdown.
HasData es una plataforma de recolección de datos web que automatiza la extracción a escala para equipos de producto. Ofrece APIs de scraping, scrapers no-code y datasets, gestionando proxies, renderizado de JavaScript y CAPTCHAs con un 99.9% de uptime. Ideal para alimentar modelos de IA y pipelines de datos con información estructurada.
2026-05-17
55.3K

HasData Información del producto
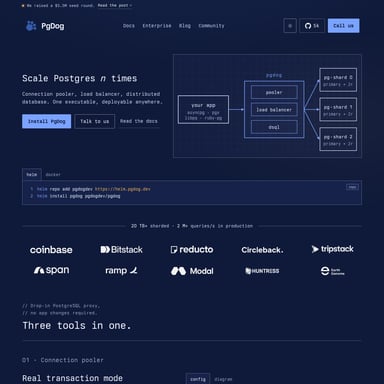
HasData: La Solución Definitiva de Web Scraping para Pipelines de Datos e IA
En el ecosistema digital actual, la capacidad de recolectar datos de manera eficiente y escalable es una ventaja competitiva crítica. HasData se posiciona como el servicio de web scraping líder diseñado específicamente para equipos de producto y desarrolladores que necesitan automatizar la recopilación de datos web a escala sin las complicaciones de la infraestructura tradicional. Con HasData, es posible transformar cualquier URL en contenido estructurado en formato JSON o Markdown mediante una sola llamada a la API, eliminando los bloqueos y garantizando la entrega de datos limpios.
¿Qué es HasData?
HasData es un pipeline de scraping gestionado que permite a las empresas centrarse en el análisis de datos en lugar de en la creación y mantenimiento de scrapers que se rompen constantemente. La plataforma actúa como un intermediario inteligente que maneja toda la complejidad técnica detrás de la extracción de datos: desde la rotación de proxies y el renderizado de navegadores headless hasta la resolución de CAPTCHAs y la gestión de reintentos.
Ya sea que necesites extraer información para alimentar modelos de Inteligencia Artificial (LLMs), construir herramientas de seguimiento de SEO o enriquecer bases de datos de leads, HasData ofrece una infraestructura robusta con un tiempo de respuesta mediano de solo 2.3 segundos y un compromiso de disponibilidad del 99.9%.
Características Principales de HasData
La versatilidad de HasData se refleja en su amplio conjunto de herramientas y capacidades técnicas diseñadas para superar cualquier obstáculo en la web moderna.
1. Infraestructura de Scraping sin Complicaciones
HasData proporciona una canalización de scraping gestionada. Simplemente envías una URL y recibes datos limpios. La plataforma se encarga de:
- Renderizado de navegadores Headless: Ejecución de miles de instancias para procesar contenido dinámico, SPAs y aplicaciones basadas en JavaScript (React, Angular, Vue).
- Rotación automática de proxies: Acceso a un grupo de más de 10 proveedores de proxies y una red residencial privada con geo-targeting incluido.
- Bypass de seguridad avanzado: Gestión automática de CAPTCHAs, detección de bots, WAF (Web Application Firewall) e incluso bypass de huellas digitales de IP.
2. APIs de Scraping Especializadas
HasData ofrece más de 40 endpoints de API optimizados para los objetivos de scraping más populares, con precios que comienzan desde los $0.08 por cada 1,000 solicitudes exitosas:
- Web Scraping API: Extracción general con soporte para IA, obteniendo títulos, descripciones, imágenes, enlaces, contenido y datos estructurados.
- Google SERP API: Datos de búsqueda en tiempo real, incluyendo resultados orgánicos, resúmenes de IA, anuncios, mapas, noticias y preguntas relacionadas.
- Google Maps Search API: Extracción de datos de ubicación como ID de lugar, dirección, teléfono, sitio web, horarios, calificaciones y reseñas.
- Otras APIs potentes: Incluye Google News, Google Flights (para datos de viajes detallados) y Google Immersive Product API (para datos de comercio electrónico como precios, vendedores y especificaciones).
3. Scrapers No-Code y Datasets
Para aquellos que prefieren una solución sin programación, los No-Code Scrapers permiten configurar extracciones en una interfaz visual, programar ejecuciones y exportar resultados en CSV, XLSX o JSON. Además, HasData ofrece datasets listos para usar de fuentes populares, permitiendo saltarse el proceso de scraping por completo.
4. Extracción con Inteligencia Artificial
Mediante el uso de prompts en lenguaje natural, la funcionalidad de AI Extraction puede convertir cualquier sitio web en un JSON estructurado de forma automática, facilitando la integración de datos web en aplicaciones de IA modernas.
Casos de Uso de HasData
La flexibilidad de las herramientas de HasData permite su aplicación en diversas industrias y necesidades técnicas.
Rastreador de Rankings para SaaS de SEO
Equipos de productos de SEO utilizan la Google SERP API para entregar datos de posicionamiento a sus clientes hasta tres veces más rápido. Al delegar la infraestructura de scraping a HasData, pueden centrarse en las funcionalidades principales de su software mientras obtienen datos precisos y en tiempo real.
Enriquecimiento de Datos de Email y Leads
Utilizando la búsqueda en Google a través de la API de HasData, empresas de generación de leads han logrado aumentar su cobertura de correos electrónicos verificados hasta cuatro veces en comparación con herramientas tradicionales como Hunter o Clearbit, enriqueciendo sus bases de datos con información pública fresca.
Alimentación de Modelos de IA y LLMs
Gracias a la capacidad de convertir sitios web complejos en Markdown o JSON estructurado, los desarrolladores pueden alimentar directamente sus modelos de lenguaje con datos actualizados de la web, garantizando que sus aplicaciones de IA tengan acceso a la información más reciente.
Cómo Utilizar HasData
Integrar HasData en tu flujo de trabajo es un proceso sencillo diseñado para desarrolladores:
- Selecciona tu herramienta: Elige entre las APIs especializadas o los scrapers no-code.
- Configura la solicitud: Define la URL de destino y los parámetros necesarios (como la ubicación para Google Search o el tipo de salida).
- Integración mediante SDK: Utiliza los SDKs oficiales para Python o NodeJS para conectar las APIs a tu aplicación en cuestión de minutos.
- Recibe datos estructurados: Obtén la respuesta en JSON listo para ser procesado por tu pipeline de datos.
"HasData ofrece exactamente lo que necesitamos: velocidad y funciones de búsqueda completas. Es la API más rápida que hemos usado en este espacio."
Preguntas Frecuentes (FAQ)
¿Qué es HasData?
Es un servicio integral de web scraping que ofrece APIs y herramientas sin código para recolectar datos de internet de forma automatizada, gestionando bloqueos, proxies y renderizado dinámico.
¿Puedo probar HasData de forma gratuita?
Sí, puedes comenzar con un plan gratuito que incluye 1,000 llamadas a la API sin necesidad de tarjeta de crédito para explorar todas las funciones.
¿Qué sucede si mi solicitud de scraping falla?
En HasData, solo pagas por los resultados exitosos. La plataforma maneja automáticamente los reintentos y la rotación de proxies para maximizar la tasa de éxito.
¿Ofrecen soluciones de scraping personalizadas?
Sí, además de los scrapers preconfigurados, HasData ofrece soluciones de scraping personalizadas para necesidades específicas de datos recurrentes o a gran escala.
¿Es legal el web scraping con HasData?
HasData cumple con las regulaciones de acceso a datos de EE. UU. y la UE, centrándose exclusivamente en la recolección de datos que son accesibles públicamente en la web.
Planes y Precios
HasData ofrece una estructura de precios flexible que escala con tu crecimiento:
- Free ($0/mes): 1,000 solicitudes y 1 solicitud concurrente.
- Startup ($49/mes): 200,000 solicitudes y 15 solicitudes concurrentes.
- Business ($99/mes): 1,000,000 solicitudes y 30 solicitudes concurrentes.
- Enterprise ($249/mes): 3,000,000 solicitudes y 50 solicitudes concurrentes.
Todos los planes de pago incluyen soporte para bypass de CAPTCHAs, rotación de User-Agent, renderizado de JavaScript y bypass de WAF.