OpenObserve
OpenObserve: High-Performance, Open-Source, Petabyte-Scale Observability Platform
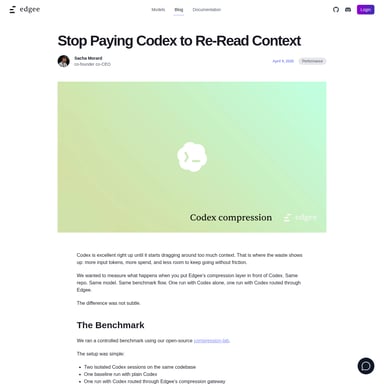
OpenObserve is a modern, unified observability platform built for the AI era, offering logs, metrics, and traces at 140x lower storage costs than traditional solutions. Written in Rust and utilizing Apache Parquet, it provides blazing-fast performance and petabyte-scale scalability. This open-source alternative to Elasticsearch and Datadog supports S3-compatible storage and stateless horizontal scaling for enterprise-grade reliability.
2026-03-20
--K

OpenObserve Product Information
OpenObserve: The High-Performance Open-Source Observability Platform
In the modern era of high-scale computing and artificial intelligence, legacy monitoring tools often become cost-prohibitive and technically cumbersome. OpenObserve emerges as a revolutionary, high-performance, and unified observability platform designed to handle the demands of the AI era. By offering an open-source, petabyte-scale solution, OpenObserve provides organizations with the ability to manage logs, metrics, traces, and frontend monitoring at a fraction of the cost of traditional competitors.
What's OpenObserve?
OpenObserve is a cloud-native observability platform engineered for extreme efficiency and performance. Built on the Rust programming language and utilizing Apache Parquet for columnar storage, OpenObserve is designed to be a lightweight yet powerful alternative to platforms like Elasticsearch and Datadog.
At its core, OpenObserve is built for the "Open" philosophy, adhering to open-source standards and protocols. It allows companies—from Fortune 500 giants to innovative startups—to gain deep insights into their infrastructure without the massive price tag. With a reported 140x lower storage cost compared to legacy solutions, OpenObserve enables long-term data retention through a "Bring Your Own Bucket" (BYOB) storage model, supporting S3, GCS, MinIO, and Azure Blob Storage.
Key Features of OpenObserve
OpenObserve is packed with enterprise-grade features that prioritize speed, cost-effectiveness, and ease of use. Below are the core pillars that make OpenObserve a leader in the observability space:
1. Exceptional Efficiency and Cost Savings
- 140x Lower Storage Costs: Benchmarked against Elasticsearch, OpenObserve significantly reduces the financial burden of data ingestion and storage.
- High Compression: Utilizes advanced compression techniques (approximately 40x) using Apache Parquet columnar storage.
- Storage Flexibility: Supports local disk and cloud-native storage including AWS S3, MinIO, GCS, and Azure Blob Storage.
2. Blazing Performance
- Rust-Powered Engine: Built with Rust for memory safety and high-speed execution.
- DataFusion Query Engine: OpenObserve utilizes the DataFusion query engine to execute lightning-fast queries directly against Parquet files.
- Proven Speed: Internal benchmarking has demonstrated the ability to query 1 petabyte of data in just 2 seconds.
3. Petabyte-Scale Scalability
- Stateless Architecture: The platform uses a stateless node architecture, allowing for seamless horizontal scaling without the complexities of data sharding or cluster rebalancing.
- Enterprise Reliability: Currently providing self-hosted logging for Fortune 100 Enterprises and used by over 6,000 companies.
- Advanced Caching: Employs result and disk caching to maintain high performance even as data volumes grow to the petabyte level.
4. Unified Observability Ecosystem
- Full Spectrum Monitoring: A single platform for Logs, Metrics, Traces, and Frontend Monitoring.
- Open Standards: Fully compatible with OpenTelemetry, ensuring easy integration with modern application stacks.
- Visualizations and Alerts: Includes powerful built-in dashboards, visualization tools, and alerting pipelines to stay ahead of system issues.
Use Cases for OpenObserve
OpenObserve is versatile enough to handle a wide range of monitoring scenarios across different cloud environments and architectures:
- Kubernetes Monitoring: Gain deep visibility into containerized workloads and cluster health.
- Cloud Infrastructure Monitoring: Purpose-built solutions for AWS Monitoring, Azure Monitoring, and GCP Monitoring.
- Database Observability: Monitor the performance and health of your critical database systems.
- Log Consolidation: Migrate from expensive SaaS providers like Datadog to a cost-effective, self-hosted or managed OpenObserve instance.
- Enterprise Compliance: With SOC2 Type II certification, OpenObserve is suitable for highly regulated industries requiring secure and auditable observability data.
"OpenObserve has proven to be a reliable and cost-effective solution built to address real-world challenges." — Wayne Creel, CTO, ONEngine
How to Use OpenObserve
Getting started with OpenObserve is designed to be remarkably fast. As noted by industry experts, a Proof of Concept (POC) can be established in as little as two to three minutes.
- Deployment: Choose between the OpenObserve Cloud (Get Started Free) or a self-hosted installation using the open-source AGPL-3.0 licensed code.
- Data Ingestion: Configure your data sources using OpenTelemetry or standard API interfaces. OpenObserve supports various pipelines for logs, metrics, and traces.
- Storage Configuration: Point the platform to your preferred storage bucket (S3, GCS, or Azure Blob) to take advantage of high compression and low-cost long-term storage.
- Query and Visualize: Use the intuitive dashboard to run queries via the DataFusion engine and build visualizations to monitor your system's health in real-time.
FAQ
Q: How does OpenObserve achieve such low storage costs? A: OpenObserve uses Apache Parquet for columnar storage and high-ratio compression (~40x). By allowing users to store data in their own low-cost cloud buckets (like S3), it eliminates the heavy markup associated with proprietary storage formats.
Q: Is OpenObserve truly open source? A: Yes, OpenObserve is licensed under AGPL-3.0, ensuring the code is transparent, auditable, and open for community contribution.
Q: Can OpenObserve handle petabyte-scale data? A: Absolutely. Its stateless architecture and efficient query engine are specifically designed to scale horizontally to handle petabytes of data while maintaining sub-second or multi-second query response times.
Q: How fast is the migration from other platforms? A: In a recent case study, DevZero successfully migrated from Datadog to OpenObserve in under an hour, demonstrating the platform's ease of integration.
Q: Does it support OpenTelemetry? A: Yes, OpenObserve is fully OpenTelemetry compatible, making it easy to plug into existing observability workflows without vendor lock-in.