Crawler.sh
Crawler.sh:全能网站爬取、SEO分析与Markdown内容提取工具
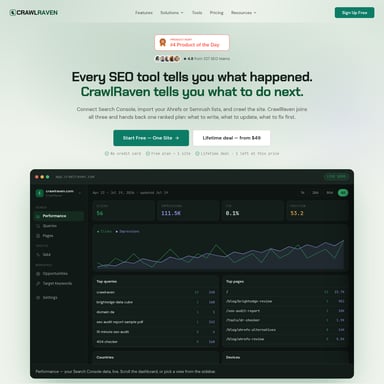
Crawler.sh 是一款专为 SEO 审计、内容存档和站点监控设计的快速网站爬虫工具。它提供桌面应用与 CLI 版本,能够秒级爬取全站,自动执行 16 项 SEO 检查,提取正文为干净的 Markdown 格式,并支持导出 JSON、Sitemap XML 及 CSV。无论是生成站点地图还是进行深度 SEO 报告,Crawler.sh 都能在本地安全、高效地完成任务,是提升网站优化效率的专业利器。
2026-03-04
--K

Crawler.sh 产品信息
Crawler.sh:高效网站爬取、SEO 深度分析与数据导出专家
在当今数字化竞争激烈的环境中,快速获取网站数据并进行精准的 SEO 审计是提升竞争力的关键。Crawler.sh 是一款专为开发者、SEO 专家和内容管理员打造的高效工具,支持在几秒钟内完成网站爬取、分析及导出。无论您需要监控站点健康状况,还是提取纯净的内容存档,Crawler.sh 都能为您提供本地化、隐私友好且性能卓越的解决方案。
什么是 Crawler.sh?
Crawler.sh 是一款集成了桌面应用程序与命令行界面(CLI)的多功能网站爬虫工具。它的核心定位是“秒级爬取、分析与导出任何网站”。该产品通过本地运行,确保了数据的私密性与极高的执行效率。
利用 Crawler.sh,用户可以轻松探索整个域名下的网页,识别复杂的 SEO 问题,可视化 HTTP 状态码,并将抓取结果转化为多种结构化格式。无论是 v0.2.3 版本新增的自定义 User-Agent 支持,还是其强大的内容提取功能,都让 Crawler.sh 成为目前市面上极具竞争力的爬虫与分析工具。
Crawler.sh 的核心功能
1. 极速全站爬取 (Site Crawling)
Crawler.sh 能够在保持在同一域名内的前提下,在几秒钟内抓取整个站点。用户可以灵活配置以下参数:
- 并发数:调整抓取速度以平衡效率与服务器压力。
- 深度限制:精确控制爬虫抓取的层级。
- 礼貌延迟:在请求之间设置延迟,确保对目标服务器友好。
- 大规模处理:性能足以支撑包含数千个页面的大型网站。
2. 自动化 SEO 分析 (SEO Analysis)
每一页抓取到的内容都会经过 16 项自动化检查。Crawler.sh 会自动检测并报告以下问题:
- 缺失的标题 (Missing Titles)
- 重复的元描述 (Duplicate Meta Descriptions)
- Noindex 指令检测
- 稀薄内容识别 (Thin Content)
- URL 过长问题
- 以及更多影响排名的关键因素。
3. 内容提取与 Markdown 转换 (Content Extraction)
Crawler.sh 能够从任何页面中提取主体文章内容,并将其自动转换为干净的 Markdown 格式。此外,它还会记录每页的:
- 字数统计 (Word Count)
- 作者署名 (Author Byline)
- 页面摘要 (Excerpt)
4. 多格式输出支持 (Multiple Output Formats)
为了适配各种工作流,Crawler.sh 支持多种数据导出方式:
- NDJSON:在爬取过程中实时流式输出。
- JSON 数组:标准的结构化数据导出。
- Sitemap XML:生成符合 W3C 标准的站点地图。
- CSV/TXT:针对 SEO 报告的专用格式,方便团队协作。
如何使用 Crawler.sh
Crawler.sh 提供了极其简单的操作逻辑,特别是其 CLI 工具,只需简单的命令即可启动复杂的任务。
基础爬取示例
使用默认设置(抓取 100 页,深度为 10)爬取一个网站:
crawler crawl https://example.com
输出结果将保存为 example-com.crawl (NDJSON 格式)。
典型工作流程
- 基本爬取 (Basic Crawl):快速获取站点概貌。
- 深度爬取 (Deep Crawl):彻底挖掘网站深层链接。
- 结果检查 (Inspect Results):查看实时抓取反馈与状态码。
- SEO 报告 (SEO Report):运行自动化检查并导出问题清单。
- 数据导出 (Export Formats):根据需求选择 JSON、XML 或 CSV。
- 全管线操作 (Full Pipeline):将爬取、分析与导出整合进自动化流程。
Crawler.sh 的应用场景
SEO 审计
运行 16 项自动化检查,在 SEO 问题影响排名之前,先于竞争对手发现缺失标题、重复描述和薄弱内容。
内容存档
将任何网站的可读内容提取为纯净的 Markdown 文件。这对于网站迁移、数据备份或为 LLM(大语言模型)提供训练素材非常完美。
站点地图生成
直接从实时爬取结果中生成符合 W3C 标准的 Sitemap XML,无需手动维护,确保搜索引擎抓取到的总是最新页面。
站点监控
定期爬取您的网站,在访问者发现之前,先识别出死链(Broken Links)、缺失页面以及 HTTP 状态码的变化。
常见问题解答 (FAQ)
Q: Crawler.sh 支持自定义 User-Agent 吗? A: 是的,在 v0.2.3 版本中,Crawler.sh 已正式增加对自定义 User-Agent 的支持,方便用户模拟不同的浏览器或爬虫身份。
Q: 一个订阅是否可以同时使用 CLI 和桌面端? A: 是的。无论是价值 $99/年的 CLI 工具还是 Desktop Pro 版本,一个订阅即可涵盖两者。CLI 专注于高效 Subcommands(如 crawl, info, export),而桌面版提供 8 个交互式卡片的视觉仪表盘。
Q: Crawler.sh 是云端运行还是本地运行? A: Crawler.sh 是一款本地优先(Local-first)的应用。它在您的机器上运行,不仅速度极快,而且对您的抓取数据提供隐私保护。
Q: 导出的 SEO 报告包含哪些内容? A: 报告包含 16 类 SEO 问题的详细分析,支持导出为 CSV 或易于阅读的 TXT 格式,方便直接发送给开发团队进行修复。