PHBench
PHBench: Innowacyjny benchmark do przewidywania finansowania Series A na podstawie danych z Product Hunt
PHBench to otwarty benchmark wykorzystujący 67 292 premier na Product Hunt do trenowania modeli przewidujących rundę finansowania Series A, oferujący unikalne dane i rankingi.
2026-05-17
--K

PHBench Informacje o produkcie
PHBench: Kompleksowy benchmark do przewidywania finansowania Series A na podstawie sygnałów z Product Hunt
Przewidywanie, który startup osiągnie sukces i pozyska znaczące finansowanie, od lat jest wyzwaniem dla inwestorów venture capital i analityków rynkowych. PHBench to przełomowy, otwarty benchmark zaprojektowany specjalnie w celu rozwiązania tego problemu poprzez analizę sygnałów z premier na platformie Product Hunt. Dzięki wykorzystaniu zaawansowanych modeli uczenia maszynowego i ogromnego zestawu danych, PHBench pozwala na identyfikację „igły w stogu siana” – czyli tych nielicznych projektów, które w ciągu 18 miesięcy od debiutu pozyskują rundę finansowania Series A.
Co to jest PHBench?
PHBench to specjalistyczne narzędzie badawcze i zestaw danych służący do oceny zdolności modeli AI do przewidywania przyszłego sukcesu finansowego startupów. Podstawą projektu jest analiza 67 292 premier na Product Hunt, które miały miejsce w ciągu ostatnich siedmiu lat (od 2019 do 2025 roku).
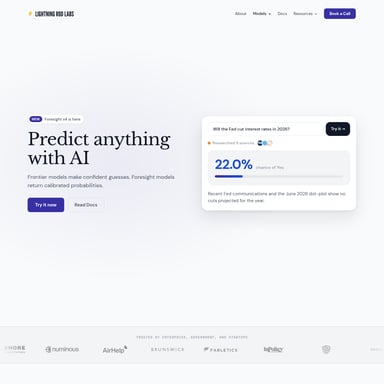
Statystyki są nieubłagane: tylko 0,78% wszystkich premier na tej platformie kończy się pozyskaniem Series A. PHBench dostarcza ramy do trenowania i rankingowania modeli, które potrafią wyłuskać te obiecujące projekty z ogromnej masy debiutów. Najlepsze modele dostępne w ramach PHBench osiągają aż 4,7-krotnie lepsze wyniki niż dobór losowy, co stanowi potężne narzędzie w rękach analityków.
Kluczowe cechy PHBench (Features)
Benchmark PHBench wyróżnia się na tle innych narzędzi analitycznych kilkoma istotnymi cechami, które czynią go standardem w dziedzinie analityki startupowej:
- Ogromny zbiór danych: Analiza obejmuje siedem lat działalności platformy, co daje łączną liczbę 67 292 przeanalizowanych premier.
- Zweryfikowane sukcesy: W zbiorze danych zidentyfikowano 528 potwierdzonych rund Series A, co stanowi bazę do nauki dla modeli.
- Precyzyjne okno czasowe: Sukces jest definiowany jako otrzymanie term sheetu na Series A w ciągu 18 miesięcy od premiery na Product Hunt.
- Zróżnicowana metodologia: PHBench wspiera różne podejścia, od regresji logistycznej (LR), przez modele XGBoost i LightGBM (LGBM), aż po nowoczesne duże modele językowe (LLM), takie jak Google Gemini.
- Transparentność i powtarzalność: Każdy model w rankingu jest poddawany audytowi, a funkcje (features) są dokładnie dokumentowane.
- Wysoka wydajność: Najlepszy obecnie model (Top-3 Ensemble) osiąga imponujące wyniki wskaźników takich jak AUC (0.840) oraz lift względem bazy.
Sygnały a szum: Co naprawdę przewiduje sukces?
Jednym z najciekawszych elementów PHBench jest analiza 61 zaprojektowanych cech (features), z których tylko 12 stanowi realny sygnał, a 4 są uznawane za czysty szum.
Kluczowe sygnały (Signal):
- Dzienny ranking premiery: Produkty, które zajmują miejsca w pierwszej trójce (Top-3) w dniu premiery, pozyskują Series A 3,5 raza częściej niż wynosi średnia rynkowa.
- Interakcja głosów i rankingu: Złożona relacja między liczbą głosów a zajętą pozycją.
- Liczba obserwujących twórcę (Maker Follower Count): Skalowana logarytmicznie, wskazuje na autorytet autorów.
- Stosunek głosów do komentarzy: Wskaźnik zaangażowania społeczności.
- Przynależność do klastra B2B: Startupy działające w modelu Business-to-Business wykazują wyższą skłonność do finansowania.
- Interakcja tematu AI z rokiem: Dynamika popularności sztucznej inteligencji w danym czasie.
Szum (Noise) – parametry o niskim znaczeniu:
- Surowa liczba głosów (Upvote count) w ujęciu logarytmicznym.
- Sam label „AI” bez kontekstu czasowego.
- Liczba słów w haśle reklamowym (tagline).
- Dzień tygodnia premiery (choć okno wtorek-czwartek jest analizowane, nie zawsze jest decydujące).
Przypadki użycia (Use Case)
PHBench znajduje zastosowanie w wielu obszarach ekosystemu startupowego:
1. Fundusze Venture Capital
Inwestorzy mogą wykorzystywać modele oparte na PHBench do automatycznego filtrowania codziennych premier na Product Hunt. Zamiast ręcznie przeglądać setki projektów, mogą skupić się na tych, które algorytm oznaczył jako mające najwyższe prawdopodobieństwo pozyskania Series A.
2. Założyciele Startapów
Twórcy mogą analizować dane z PHBench, aby zrozumieć, jakie parametry ich premiery korelują z przyszłym zainteresowaniem inwestorów. Choć rankingu nie da się w pełni kontrolować, zrozumienie wagi zaangażowania społeczności czy doboru kategorii (np. B2B) jest kluczowe.
3. Badacze Danych i AI
Specjaliści od uczenia maszynowego mogą testować swoje własne modele na udostępnionym zbiorze danych phbench_public_test.csv, porównując swoje wyniki z globalnym rankingiem (Leaderboard), na którym znajdują się rozwiązania od Google czy czołowych badaczy.
Jak korzystać z PHBench? (How to Use)
Aby w pełni wykorzystać potencjał PHBench, użytkownicy mogą podjąć następujące kroki:
- Analiza Rankingu (Leaderboard): Przeglądaj aktualne wyniki modeli, takich jak XGB_m21 czy ENS_avg, aby zrozumieć, które metody predykcji są obecnie najskuteczniejsze.
- Pobieranie danych: Skorzystaj z publicznie dostępnych zestawów danych do trenowania własnych modeli predykcyjnych.
- Przesyłanie prognoz (Submit Predictions): Badacze mogą przesyłać własne wyniki w celu ich weryfikacji na ukrytym zbiorze testowym i powalczyć o miejsce na podium.
- Subskrypcja prognoz: Istnieje możliwość otrzymywania cotygodniowych prognoz dotyczących najnowszych premier, co pozwala trzymać rękę na pulsie najciekawszych projektów.
FAQ – Najczęściej zadawane pytania
P: Czy każda popularna premiera na Product Hunt oznacza sukces finansowy? O: Nie. Jak wykazuje PHBench, wiele popularnych produktów (wysoka liczba głosów) to jedynie „szum”. Kluczowe jest zajęcie wysokiego miejsca w rankingu dziennym (Top-3), co zwiększa szanse na Series A aż 3,5-krotnie.
P: Jakie modele radzą sobie najlepiej w benchmarku PHBench? O: Obecnie najwyższe wyniki osiągają ansamble modeli (Top-3 Ensemble), łączące XGBoost i LightGBM z kalibracją izotoniczną. Modele LLM, takie jak Gemini 3 Flash, radzą sobie dobrze, ale wciąż ustępują wyspecjalizowanym modelom tabularycznym.
P: Co oznacza „lift over random”? O: Jest to wskaźnik mówiący o tym, o ile skuteczniejszy jest model od losowego zgadywania. Najlepsze modele w PHBench osiągają współczynnik 4,7x, co oznacza znaczną przewagę analityczną.
P: Czy dane w PHBench są aktualizowane? O: Tak, benchmark obejmuje dane od 2019 roku aż do 2025 roku, uwzględniając najnowsze trendy rynkowe, takie jak dynamiczny rozwój sektora AI.
PHBench stanowi rozszerzenie projektu VCBench i jest wynikiem pracy zespołu w składzie: Yagiz Ihlamur, Ben Griffin oraz Rick Chen. Wszystkie wyniki są weryfikowalne i możliwe do zacytowania w pracach naukowych.