Crawler.sh
Crawler.sh: Herramienta de Rastreo Web, Análisis SEO y Extracción de Contenido a Markdown
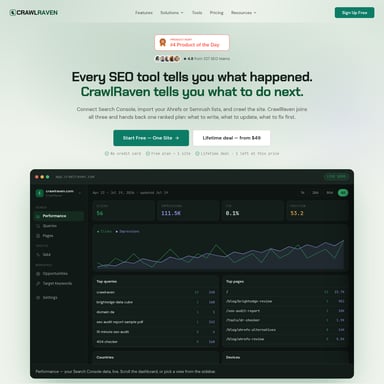
Crawler.sh es una potente aplicación de escritorio y herramienta CLI diseñada para rastrear sitios web completos en segundos. Permite analizar problemas de SEO mediante 16 comprobaciones automáticas, visualizar códigos de estado HTTP y extraer contenido legible directamente en formato Markdown. Con soporte para múltiples formatos de exportación como JSON, Sitemap XML y NDJSON, Crawler.sh es la solución ideal para auditorías SEO, generación de sitemaps y archivado de contenido. Funciona de manera local, rápida y centrada en la privacidad, ofreciendo flexibilidad total para expertos en marketing y desarrolladores.
2026-03-04
--K

Crawler.sh Información del producto
Crawler.sh: La Solución Definitiva para Rastrear, Analizar y Exportar Sitios Web
En el ecosistema digital actual, la capacidad de procesar datos web de manera rápida y eficiente es fundamental. Crawler.sh surge como una herramienta integral, disponible tanto en aplicación de escritorio como en interfaz de línea de comandos (CLI), diseñada para rastrear sitios web, realizar un análisis SEO profundo y exportar resultados en múltiples formatos en cuestión de segundos.
¿Qué es Crawler.sh?
Crawler.sh es una herramienta de alto rendimiento que permite a los usuarios rastrear sitios web completos de forma local, garantizando privacidad y velocidad. Ya sea que necesites auditar el SEO de una página, generar un sitemap o extraer contenido para migraciones, Crawler.sh ofrece una infraestructura robusta que funciona directamente desde tu máquina.
Este software destaca por su versatilidad, ofreciendo una Desktop App profesional con paneles visuales y una CLI Tool potente para integrarse en flujos de trabajo automatizados. Con la versión v0.2.3, ahora incluye soporte para User-Agent personalizado, permitiendo una mayor flexibilidad durante el rastreo.
Características Principales de Crawler.sh
Crawler.sh ha sido diseñado con un enfoque en la eficiencia y la profundidad de los datos. A continuación, se detallan sus funcionalidades clave:
Rastreo de Sitios (Site Crawling)
- Velocidad Extrema: Rastrea sitios completos en segundos manteniéndose dentro del mismo dominio.
- Configuración Avanzada: Permite ajustar la concurrencia, los límites de profundidad y establecer retrasos de cortesía (polite delay) entre solicitudes.
- Escalabilidad: Capaz de manejar miles de páginas sin comprometer el rendimiento.
Extracción de Contenido
- Markdown Limpio: Extrae el contenido principal de cualquier página y lo convierte automáticamente a Markdown legible.
- Metadatos Detallados: Incluye conteo de palabras, firma del autor y un extracto de cada página rastreada.
Análisis SEO Automatizado
- 16 Comprobaciones Automáticas: Detecta problemas críticos como títulos faltantes, descripciones meta duplicadas, directivas noindex, contenido delgado (thin content) y URLs excesivamente largas.
- Visualización de Estados: Identifica y visualiza códigos de estado HTTP para detectar enlaces rotos o errores de servidor.
Múltiples Formatos de Salida
- Exportación Flexible: Soporta formatos NDJSON, JSON, Sitemap XML, CSV y TXT.
- Flujo en Tiempo Real: Transmite resultados como NDJSON durante el proceso de rastreo.
Casos de Uso (Use Case)
Crawler.sh se adapta a diversas necesidades profesionales gracias a su arquitectura flexible:
- Auditoría SEO: Ejecuta las 16 comprobaciones automáticas en cada página para encontrar errores que afectan el ranking antes de que los buscadores los penalicen.
- Archivado de Contenido: Perfecta para copias de seguridad o migraciones de sitios web, convirtiendo el contenido en Markdown para facilitar su uso en otras plataformas.
- Generación de Sitemaps: Crea archivos Sitemap XML compatibles con W3C a partir de un rastreo en vivo, manteniendo el índice de tu sitio actualizado sin esfuerzo manual.
- Monitoreo de Sitios: Rastrea regularmente tu sitio para capturar enlaces rotos y cambios en los códigos de estado antes de que los visitantes los encuentren.
Cómo Usar Crawler.sh (How to Use)
El uso de Crawler.sh es intuitivo tanto para usuarios técnicos como para aquellos que prefieren interfaces gráficas.
Uso de la CLI
Para realizar un rastreo básico con la herramienta de línea de comandos, simplemente utiliza el siguiente comando:
crawler crawl https://ejemplo.com
Esto iniciará un rastreo con la configuración por defecto (hasta 100 páginas y profundidad 10), generando un archivo de salida en formato .crawl (NDJSON).
Flujo de Trabajo en la App de Escritorio
- Iniciar Rastreo: Introduce la URL y configura los límites deseados.
- Inspeccionar Resultados: Utiliza el panel de problemas SEO para ver detalles por URL.
- Visualizar: Observa el feed en tiempo real con insignias de estado y tarjetas interactivas.
- Exportar: Selecciona el formato deseado (JSON, XML, CSV o Markdown) para procesar los datos con tu equipo.
Preguntas Frecuentes (FAQ)
¿Qué incluye la suscripción a Crawler.sh?
Una única suscripción anual de $99 cubre tanto la herramienta CLI como la Desktop App Pro. Esto te da acceso a todas las funciones de análisis SEO, extracción de contenido y múltiples formatos de exportación.
¿Es Crawler.sh una herramienta basada en la nube?
No, es una herramienta local-first. Esto significa que el rastreo se realiza desde tu propia máquina, lo que garantiza una mayor privacidad y velocidad al no depender de servidores externos para el procesamiento de datos.
¿Qué tipos de análisis SEO realiza?
Realiza 16 categorías de análisis, incluyendo la detección de títulos faltantes, meta descripciones duplicadas, URLs largas, contenido delgado y directivas de rastreo como noindex.
¿Puedo generar sitemaps con esta herramienta?
Sí, Crawler.sh permite exportar un Sitemap XML compatible con los estándares de W3C directamente desde los resultados del rastreo.
¿En qué formatos puedo obtener el contenido extraído?
El contenido de los artículos se extrae principalmente como Markdown limpio, ideal para alimentar herramientas de LLMs, blogs o archivos personales.