Seed-TTS
Seed-TTS: High-Quality Autoregressive Text-to-Speech Model by ByteDance
Introduction:
Seed-TTS by ByteDance is a high-quality, versatile text-to-speech model that generates speech nearly indistinguishable from human speech. It excels in in-context learning, speaker similarity, and speech naturalness. Offering superior controllability over various speech attributes like emotion, Seed-TTS is capable of creating highly expressive and diverse speech. The model includes a non-autoregressive variant, Seed-TTS DiT, which uses a diffusion-based architecture for enhanced performance. Ideal for a variety of applications, Seed-TTS is revolutionizing speech technology.
Added On:
2024-06-22
Monthly Visitors:
2.7K

Seed-TTS Product Information
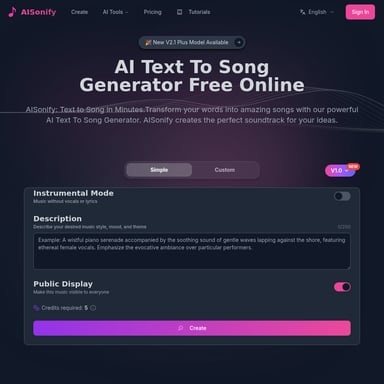
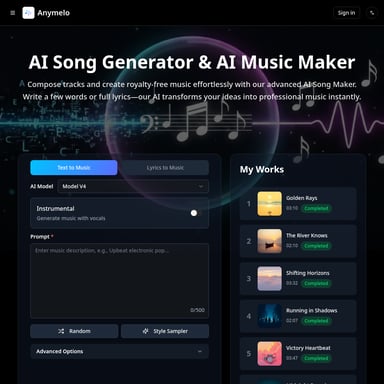
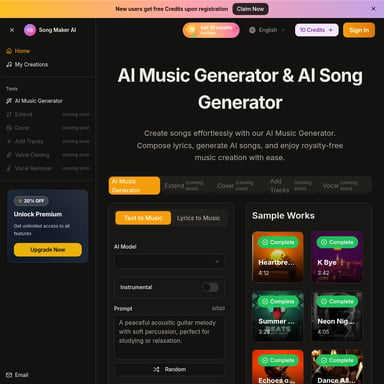
Seed-TTS\n\n### A Family of High-Quality Versatile Speech Generation Models\n\n[Paper]Seed Team\n\nByteDance\n\nAbstract. We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named Seed-TTSDiT, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, Seed-TTSDiT does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant in both objective and subjective evaluations and showcase its effectiveness in speech editing.\n\nContents\n\n* System Overview\n* Zero-shot In-context Learning\n* Speaker Fine-tune\n* Speech Factorization\n* Preference Biasing Through Reinforcement Learning\n* Fully Diffusion-based Speech Generation\n* Applications\n\n## What's Seed-TTS\n\nSeed-TTS, developed by ByteDance, is a state-of-the-art autoregressive text-to-speech (TTS) model. Seed-TTS achieves speech generation that is nearly indistinguishable from human speech, excelling in speaker similarity and naturalness. Designed as a foundation model for speech generation, it offers superior controllability over various speech attributes, including emotion, resulting in highly expressive and diverse speech outputs.\n\n## Use Case\n\nSeed-TTS is highly versatile and can be applied in myriad domains: \n\n### Content Creation\n\nContent creators can leverage Seed-TTS to produce highly natural and expressive voiceovers for videos, podcasts, and other media forms.\n\n### Assistive Technologies\n\nFor individuals with speech impairments, Seed-TTS can generate realistic and emotionally rich speech, enhancing communication tools.\n\n### Customer Service\n\nSeed-TTS can be employed to generate dynamic, natural-sounding voices for virtual assistants and automated customer service solutions, improving user experience.\n\n## Features\n\n### High-Quality Speech Generation\n\nSeed-TTS generates speech that matches ground truth human speech in speaker similarity and naturalness, as confirmed through both objective and subjective evaluations.\n\n### In-Context Learning\n\nThe model leverages speech in-context learning, allowing it to adapt to a variety of speaking styles and contexts with minimal input data.\n\n### Controllability\n\nOne of the standout features is its superior controllability over different speech attributes, particularly emotion, enabling the generation of highly expressive and diverse speech outputs.\n\n### Non-Autoregressive Variant\n\nSeed-TTS includes a non-autoregressive variant named Seed-TTSDiT, which employs a diffusion-based architecture that performs end-to-end speech generation without relying on pre-estimated phoneme durations.\n\n## How To Use\n\nUsing Seed-TTS involves a few straightforward steps: \n\n1. Access: Obtain access to the Seed-TTS model via the official platform.\n2. Input Text: Provide the text input that you want to convert into speech.\n3. Fine-Tuning: Optionally, fine-tune the model for specific speaker characteristics or emotional tone to match your requirements.\n4. Generate Speech: Use the model to generate high-quality, natural-sounding speech.\n5. Integration: Integrate the generated speech into your application, whether it's a video, virtual assistant, or any other use case.\n\n## FAQ\n\n### What is Seed-TTS?\n\nSeed-TTS is a high-quality, autoregressive text-to-speech model by ByteDance capable of generating speech that is nearly indistinguishable from human speech.\n\n### How does Seed-TTS ensure naturalness and speaker similarity?\n\nThe model excels in both objective and subjective evaluations, achieving performance that matches ground truth human speech.\n\n### Can Seed-TTS be fine-tuned?\n\nYes, Seed-TTS can be fine-tuned for higher subjective scores in various metrics including speaker similarity and emotional tone.\n\n### What is the non-autoregressive variant Seed-TTSDiT?\n\nSeed-TTSDiT is a non-autoregressive variant that uses diffusion-based architecture to perform end-to-end speech generation without pre-estimated phoneme durations.\n\n### What are the use cases for Seed-TTS?\n\nSeed-TTS can be utilized for content creation, assistive technologies, virtual assistants, and automated customer service solutions, among other applications.\n\n### How can I access Seed-TTS?\n\nYou can access Seed-TTS via the official ByteDance platform, where detailed guidelines for usage and integration are provided.
Loading related products...