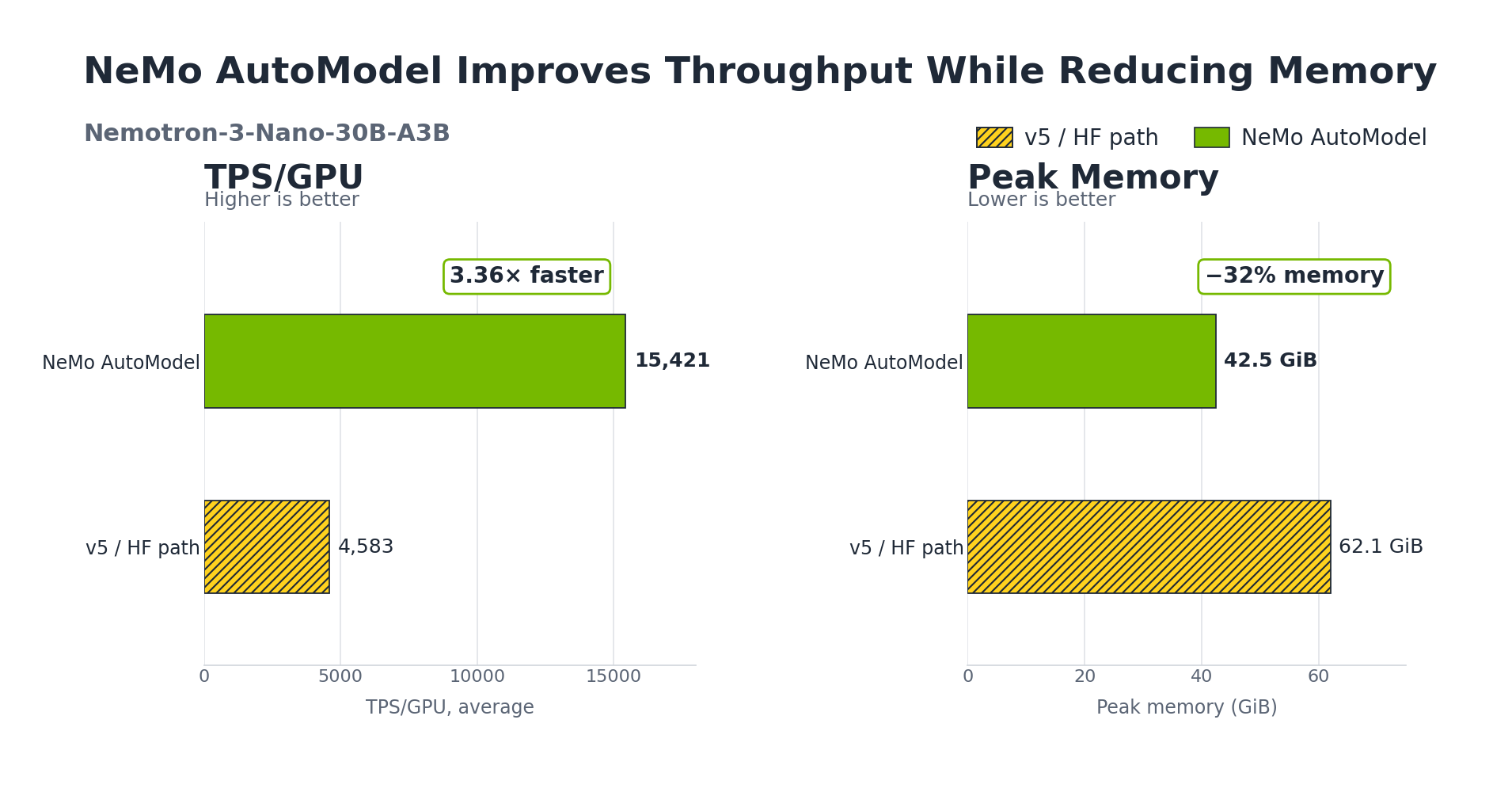
Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel: A New Standard for AI Efficiency
NVIDIA has announced the launch of NeMo AutoModel, a tool specifically engineered to accelerate the fine-tuning process for Transformer-based architectures. Featured on the Hugging Face Blog, this development represents a strategic integration between NVIDIA's robust NeMo framework and the widely used Hugging Face ecosystem. The NeMo AutoModel aims to streamline the complex workflows associated with model adaptation, allowing developers to optimize large language models (LLMs) with greater speed and less manual configuration. By focusing on the acceleration of fine-tuning, NVIDIA addresses a critical bottleneck in the AI lifecycle, potentially lowering the computational barriers for enterprises and researchers seeking to deploy specialized AI solutions across various industries.
Key Takeaways
- Introduction of NVIDIA NeMo AutoModel: A new tool designed to significantly speed up the fine-tuning of Transformer models.
- Strategic Collaboration: The announcement highlights a synergy between NVIDIA's high-performance computing tools and the Hugging Face platform.
- Focus on Efficiency: The primary goal is to reduce the time and complexity involved in adapting pre-trained models to specific tasks.
- Streamlined Workflows: NeMo AutoModel simplifies the transition from general-purpose models to domain-specific applications.
In-Depth Analysis
The Role of NVIDIA NeMo AutoModel in Modern AI
The announcement of "Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel" marks a pivotal moment in the evolution of model customization. NVIDIA NeMo has long been established as a comprehensive, cloud-native framework for building, customizing, and deploying generative AI models. The introduction of the "AutoModel" feature suggests a move toward higher levels of abstraction and automation within this framework. By targeting the fine-tuning phase—where a pre-trained Transformer model is adjusted for specific datasets—NVIDIA is addressing the most resource-intensive part of the AI development cycle. This tool likely leverages NVIDIA's hardware-software co-optimization to ensure that Transformer architectures run at peak efficiency during the gradient update process.
Optimizing Transformer Fine-Tuning Workflows
Fine-tuning Transformer models is traditionally a complex task that requires deep expertise in hyperparameter tuning, memory management, and hardware utilization. The "AutoModel" designation implies that NVIDIA is providing a more automated path for developers to achieve optimal results without exhaustive manual intervention. This acceleration is not merely about raw speed; it is about the efficiency of the entire workflow. By integrating this capability into the Hugging Face ecosystem, NVIDIA ensures that the vast community of developers using Transformers can access high-performance fine-tuning capabilities directly within their existing environments. This integration bridges the gap between open-source flexibility and enterprise-grade performance optimization.
Technical Implications for Large-Scale Models
As Transformer models continue to grow in size, the computational cost of fine-tuning becomes a significant barrier to entry. The NeMo AutoModel's focus on acceleration suggests improvements in how memory is handled and how computations are distributed across NVIDIA GPUs. For developers, this means the ability to iterate faster, testing more variations of a model in less time. The focus on "Transformers" specifically acknowledges the industry-standard architecture for natural language processing and beyond, ensuring that the tool has broad applicability across different types of generative AI tasks, from text generation to complex data analysis.
Industry Impact
The introduction of NVIDIA NeMo AutoModel is set to have a profound impact on the AI industry by democratizing access to high-performance fine-tuning. By reducing the time-to-market for specialized AI models, companies can more rapidly deploy solutions tailored to their specific data and needs. This development reinforces NVIDIA's position as a leader in the AI infrastructure space, moving beyond hardware to provide the essential software layers that make AI development practical at scale. Furthermore, the collaboration with Hugging Face strengthens the open-source AI landscape, providing professional-grade tools to a wider audience of researchers and developers, which could lead to a surge in specialized AI applications across healthcare, finance, and technology sectors.
Frequently Asked Questions
Question: What is the primary purpose of NVIDIA NeMo AutoModel?
NVIDIA NeMo AutoModel is designed to accelerate and simplify the fine-tuning process for Transformer-based models. It provides a streamlined workflow that allows developers to adapt pre-trained models to specific tasks more efficiently, leveraging NVIDIA's optimized computing framework.
Question: How does this announcement affect Hugging Face users?
Hugging Face users can benefit from the integration of NVIDIA's NeMo AutoModel capabilities, allowing them to utilize NVIDIA's acceleration technologies within the familiar Hugging Face environment. This makes it easier to perform high-performance fine-tuning on a wide range of models hosted on the platform.
Question: Why is accelerating fine-tuning important for AI development?
Fine-tuning is a critical step in making AI models useful for specific real-world applications. Accelerating this process reduces the time and computational cost required to develop specialized models, enabling faster innovation and more cost-effective AI deployment for enterprises.


